Programming Massively Parallel Processors Fourth Edition 学习摘录
本文主体摘抄于李理的博客,在其基础上选择了最核心最重要的部分,基本上是这本书的精简版,可用作复习和回顾使用
第一章:简介
1.1 异构并行计算
低延迟的算术单元、复杂的操作数传递逻辑、大缓存内存和控制逻辑消耗了本可以用于提供更多算术执行单元和内存访问通道的芯片面积和功耗。这种设计方法通常被称为面向延迟设计。
图1.1 CPU和GPU具有根本不同的设计理念:(A)CPU设计是面向延迟的;(B)GPU设计是面向吞吐量的。
一个重要的观察是,在功耗和芯片面积方面,减少延迟比增加吞吐量昂贵得多。例如,可以通过将算术单元数量翻倍来使算术吞吐量翻倍,代价是将芯片面积和功耗翻倍。然而,将算术延迟减半可能需要将电流翻倍,代价是使用的芯片面积增加超过两倍,并将功耗增加四倍。因此,GPU中的主流解决方案是优化大量线程的执行吞吐量,而不是减少单个线程的延迟。这种设计方法通过允许流水线式内存通道和算术操作具有长延迟来节省芯片面积和功耗。内存访问硬件和算术单元的面积和功耗的降低允许GPU设计者在芯片上拥有更多这些组件,从而增加总执行吞吐量。
图1.1通过图示在图1.1A的CPU设计中较少数量的较大算术单元和较少数量的内存通道,与图1.1B中较多数量的较小算术单元和较多数量的内存通道之间的设计方法差异,直观地说明了这种差异。
是的,现代高性能CPU的核心普遍采用乱序执行(Out-of-Order Execution, OoOE)技术。
正如您在问题中提到的英特尔多核服务器处理器,其每个核心都是“乱序、多指令执行处理器”。这并非特例,而是行业标准。乱序执行是现代处理器用来提升性能的一项关键技术,它允许CPU动态地重新排列指令的执行顺序,只要不违反程序的数据依赖关系,从而更充分地利用处理器内部的执行单元2。
这项技术被广泛应用于主流的高性能处理器架构中,包括Intel和AMD的x86/x86-64处理器,以及许多高性能的ARM处理器(如您提到的Ampere处理器)。可以说,只要是追求高性能的现代CPU核心,几乎都具备乱序执行能力4。
图1.1B中的小缓存存储器旨在帮助控制这些应用程序的带宽要求,以便访问相同内存数据的多个线程不必全部访问DRAM
- 很多并行线程往往会重复访问相同的数据(比如同一个像素值、同一个权重参数)。
- 如果每个线程都直接去访问主存(DRAM),会造成巨大的内存带宽压力,而且速度慢。
- 因此,GPU配备了小容量但高速的缓存(如共享内存、L1/L2缓存),把热点数据暂存起来。
- 多个线程可以共享缓存中的同一份数据,避免反复访问慢速的DRAM,从而节省带宽、提升效率。
当程序具有大量线程时,具有更高执行吞吐量的GPU可以实现比CPU高得多的性能。因此,人们应该期望许多应用程序同时使用CPU和GPU,将顺序部分在CPU上执行,将数值密集型部分在GPU上执行。这就是为什么NVIDIA在2007年推出的Compute Unified Device Architecture(CUDA)编程模型被设计为支持应用程序的联合CPU-GPU执行的原因
1.2 为什么需要更高速度或并行性?
通过大幅提高计算吞吐量实现的新应用的一个重要例子是基于人工神经网络的深度学习。尽管自上世纪70年代以来神经网络一直在积极研究,但它们在实际应用中效果不佳,因为训练这些网络需要太多标记数据和太多计算资源。互联网的兴起提供了大量标记图片,而GPU计算吞吐量的提升则带来了大量计算资源。因此,自2012年以来,基于神经网络的应用在计算机视觉和自然语言处理领域迅速得到采用。这种采用已经彻底改变了计算机视觉和自然语言处理应用,并促使了自动驾驶汽车和家庭助手设备的快速发展。
1.3 加速实际应用程序
并行计算系统相对于串行计算系统可以实现的加速度取决于可以并行化的应用程序部分。例如,如果在可以并行化的部分花费的时间百分比为 30%,那么并行部分的 100倍 速度提升将最多减少应用程序的总执行时间 29.7%。也就是说,整个应用程序的加速度只约为 1/(1-0.297)=1.423。事实上,即使在可以并行化的部分可以实现无限的速度提升,也只能在执行时间上削减 30%,最多达到 1.433 倍的速度提升。通过并行执行可以实现的速度提升水平可能受到应用程序可并行化部分的严重限制,这被称为阿姆达尔定律(Amdahl, 2013)。
影响应用程序可实现加速度水平的另一个重要因素是从内存访问数据的速度以及向内存写入数据的速度。在实践中,应用程序的直接并行化通常会饱和内存(DRAM)带宽,导致只有约 10倍 的速度提升
1.4 并行编程中的挑战
幸运的是,大多数这些挑战已经得到研究人员的解决。在不同应用领域之间存在共同的模式,允许我们将在一个领域中推导出的解决方案应用到其他领域的挑战中。这是为什么我们将在重要的并行计算模式和应用程序的上下文中呈现解决这些挑战的关键技术的主要原因。
1.5 相关的并行编程接口
在过去的几十年中,提出了许多并行编程语言和模型(Mattson等,2004)。最广泛使用的是用于共享内存多处理器系统的OpenMP(Open, 2005)和用于可伸缩集群计算的消息传递接口(MPI)(MPI, 2009)。两者都已成为主要计算机供应商支持的标准化编程接口。
OpenMP实现包括编译器和运行时。程序员通过指定关于循环的指令(commands)和编译器的提示(hints)向OpenMP编译器提供信息。使用这些指令和提示,OpenMP编译器生成并行代码。运行时系统通过管理并行线程和资源来支持并行代码的执行。OpenMP最初是为CPU执行而设计的,并已扩展以支持GPU执行。 这种自动化和抽象有助于使应用代码在由不同供应商生产的系统以及同一供应商的不同系统世代之间更具可移植性。我们将这种属性称为性能可移植性
根据我们的经验,OpenMP编译器仍在不断发展和改进。许多程序员可能需要在OpenMP编译器存在不足的部分使用CUDA风格的接口。
另一方面,MPI是一个计算节点在集群中不共享内存的编程接口(MPI, 2009)。所有数据共享和交互都必须通过显式消息传递来完成。MPI在高性能计算(HPC)中被广泛使用。在MPI中编写的应用程序已经成功在具有超过100,000个节点的集群计算系统上运行。今天,许多HPC集群使用异构的CPU/GPU节点。将应用程序移植到MPI中所需的工作量可能会相当大,这是由于计算节点之间缺乏共享内存。程序员需要进行领域分解,将输入和输出数据分区到各个节点。基于领域分解,程序员还需要调用消息发送和接收函数来管理节点之间的数据交换。相比之下,CUDA为GPU中的并行执行提供了共享内存以解决这一困难。虽然CUDA是与每个节点有效通信的接口,但大多数应用程序开发人员需要使用MPI在集群级别进行编程。此外,通过诸如NVIDIA Collective Communications Library(NCCL)的API,CUDA对多GPU编程的支持也越来越多。因此,对于在现代计算集群中使用多GPU节点的并行程序员来说,理解如何进行MPI/CUDA联合编程是非常重要的,这是在第20章“编程异构计算集群”中介绍的一个主题。
在2009年,包括苹果、英特尔、AMD/ATI和NVIDIA在内的几家主要行业参与者共同开发了一种标准化的编程模型,称为Open Compute Language(OpenCL)(The Khronos Group, 2009)。与CUDA类似,OpenCL编程模型定义了语言扩展和运行时API,以允许程序员管理大规模并行处理器中的并行性和数据传递。与CUDA相比,OpenCL更多地依赖于API,而不是语言扩展。这使得供应商可以快速调整其现有的编译器和工具以处理OpenCL程序。OpenCL是一个标准化的编程模型,使用OpenCL语言扩展和API支持的所有处理器上的应用程序可以在不修改的情况下正确运行。但是,为了在新处理器上实现高性能,可能需要修改应用程序。
熟悉OpenCL和CUDA的人会知道,在OpenCL和CUDA的关键概念和特性之间存在显着的相似性。也就是说,CUDA程序员可以在很小的努力下学习OpenCL编程。更重要的是,几乎在CUDA中学到的所有技术都可以轻松应用于OpenCL编程。
1.6 总体目标
1.7 书籍组织结构
https://fancyerii.github.io/pmpp/ch1/#12-%E4%B8%BA%E4%BB%80%E4%B9%88%E9%9C%80%E8%A6%81%E6%9B%B4%E9%AB%98%E9%80%9F%E5%BA%A6%E6%88%96%E5%B9%B6%E8%A1%8C%E6%80%A7
第二章:异构数据并行计算
为了将彩色图像(图2.1左侧)转换为灰度图像(右侧),我们通过应用以下加权和公式计算每个像素的亮度值L:
L=0.21r+0.72g+0.07b
RGB色彩图像表示
在RGB表示中,图像中的每个像素都以(r, g, b)值的元组形式存储。图像的行的格式为(r g b) (r g b) . . . (r g b),如下概念图片所示。每个元组指定了红色(R)、绿色(G)和蓝色(B)的混合。也就是说,对于每个像素,r、g 和 b 的值表示在呈现像素时红色、绿色和蓝色光源的强度(0表示黑暗,1表示完全强度)。
这三种颜色的实际允许混合方式在行业指定的色彩空间中有所不同。
任务并行性与数据并行性 在并行编程中,数据并行性并不是唯一使用的并行性类型。任务并行性在并行编程中也被广泛使用。任务并行性通常通过对应用程序的任务分解来暴露。例如,一个简单的应用程序可能需要进行矢量加法和矩阵-矢量乘法。其中每个都将是一个任务。如果这两个任务可以独立完成,那么就存在任务并行性。I/O和数据传输也是任务的常见来源。在大型应用程序中,通常存在更多独立的任务,因此也存在更多的任务并行性。
总体而言,数据并行性是并行程序可伸缩性的主要来源。
2.2 CUDA C程序结构
顾名思义,CUDA C建立在NVIDIA的CUDA平台上。CUDA目前是最成熟的用于大规模并行计算的框架,被广泛应用于高性能计算行业,提供了在大多数常见操作系统上使用的编译器、调试器和性能分析工具等基本工具。
CUDA C程序的结构反映了计算机中主机(CPU)和一个或多个设备(GPU)的共存。每个CUDA C源文件可以包含主机代码和设备代码的混合。默认情况下,任何传统的C程序都是一个只包含主机代码的CUDA程序。可以将设备代码添加到任何源文件中。设备代码使用特殊的CUDA C关键字明确定义。设备代码包括函数或内核,其代码以数据并行方式执行。
CUDA程序的执行过程如图2.3所示。执行从主机代码(CPU串行代码)开始。当调用内核函数时,在设备上启动大量线程以执行内核。由内核调用启动的所有线程被集体称为一个网格。这些线程是CUDA平台中并行执行的主要工具。图2.3显示了两个线程网格的执行过程。我们将很快讨论这些网格是如何组织的。当一个网格的所有线程都完成执行时,该网格终止,并且执行继续在主机上,直到启动另一个网格。

请注意,图2.3显示了一个简化的模型,其中CPU执行和GPU执行不重叠。许多异构计算应用程序管理重叠的CPU和GPU执行,以充分利用CPU和GPU的优势。
启动一个网格通常会生成许多线程,以利用数据并行性。在将颜色转为灰度的示例中,每个线程可以用于计算输出数组O的一个像素。在这种情况下,由网格启动生成的线程数等于图像中的像素数。对于大图像,将生成大量线程。CUDA程序员可以假设这些线程在生成和调度时需要很少的时钟周期,这归功于高效的硬件支持。这一假设与传统的CPU线程形成对比,后者通常需要数千个时钟周期来生成和调度。
线程 线程是现代计算机中处理器执行顺序程序的简化视图。一个线程包括程序的代码、正在执行的代码点以及其变量和数据结构的值。就用户而言,线程的执行是顺序的。用户可以使用源代码级调试器逐条执行语句,查看下一条将要执行的语句,并在执行过程中检查变量和数据结构的值。
线程在编程中已经使用了很多年。如果程序员希望在应用程序中启动并行执行,他/她可以使用线程库或特殊语言创建和管理多个线程。在CUDA中,每个线程的执行也是顺序的。CUDA程序通过调用内核函数启动并行执行,这会导致底层运行时机制启动一个处理不同数据部分的线程网格。
🔸 所以 CUDA 文档说“每个线程的执行也是顺序的”,指的是单个线程的语义顺序,而不是说所有线程串行执行。
四、总结:三个层次要分清
| 层次 | 描述 | 是否“顺序”? |
|---|---|---|
| 1. 编程模型 / 语言语义 | 程序员写的代码逻辑 | ✅ 必须顺序(保证正确性) |
| 2. 单线程硬件执行 | CPU/GPU核心如何执行一个线程 | ⚠️ 内部可能乱序,但结果等效于顺序 |
| 3. 多线程并发/并行 | 多个线程是否同时运行 | ❌ 并行(多个线程同时执行) |
2.3 矢量加法内核
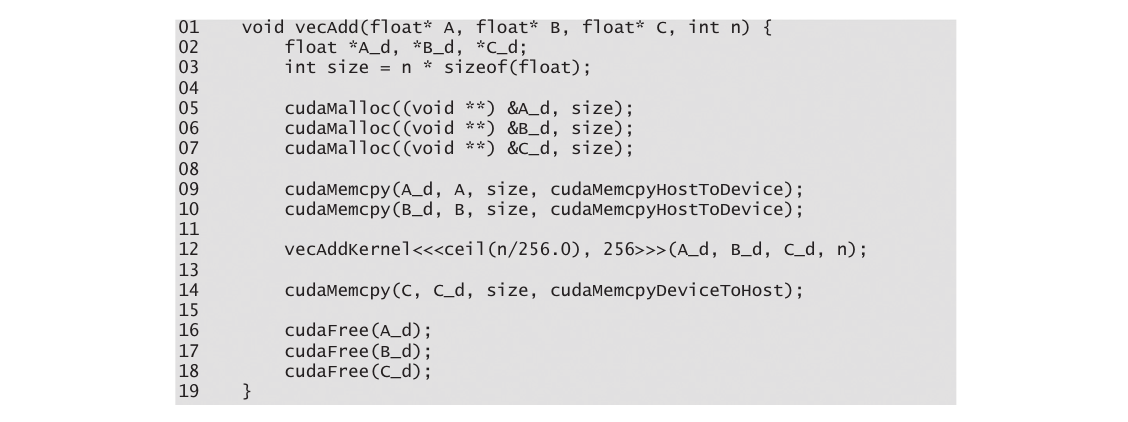
请注意,修改后的vecAdd函数本质上是一个外包代理,将输入数据发送到设备,激活设备上的计算,并从设备收集结果。该代理以一种使主程序甚至无需知道矢量加法实际上是在设备上完成的方式执行此操作。实际上,由于数据的来回复制,这种“透明”外包模型通常效率较低。通常,人们会在设备上保留大型和重要的数据结构,并仅从主机代码中调用设备函数。然而,目前我们将使用简化的透明模型来介绍基本的CUDA C程序结构。
2.4 设备全局内存和数据传输
- 对于矢量加法核函数,在调用核函数之前,程序员需要在设备全局内存中分配空间并将数据从主机内存传输到设备全局内存中的已分配空间。
- 同样,在设备执行后,程序员需要将结果数据从设备全局内存传输回主机内存,并释放在设备全局内存中分配的不再需要的空间。
- CUDA运行时系统(通常在主机上运行)提供了应用程序编程接口(API)函数,代表程序员执行这些活动。从这一点开始,我们将简单地说数据从主机传输到设备,以简称将数据从主机内存复制到设备全局内存中。相同的情况适用于相反的方向。
cudaMalloc函数的第一个参数是一个指针变量的==地址==(注意是 &A_d ! 而不是A_d),该变量将被设置为指向已分配对象的地址。指针变量的地址应强制转换为(void *),因为该函数期望一个通用指针;内存分配函数是一个通用函数,不限于任何特定类型的对象。这个参数允许cudaMalloc函数将分配的内存的地址写入提供的指针变量,而不管其类型如何。调用核函数的主机代码将此指针值传递给需要访问已分配内存对象的核函数。cudaMalloc函数的第二个参数给出要分配的数据的大小,以字节为单位。该第二个参数的使用与C malloc函数的size参数一致。
注:
- CUDA C还具有更先进的库函数,用于在主机内存中分配空间。我们将在第20章“编程异构计算集群”中讨论它们。
- 事实上,cudaMalloc返回一个通用对象,这使得使用动态分配的多维数组更加复杂。我们将在第3.2节解决这个问题。
- 请注意,cudaMalloc与C的malloc函数具有不同的格式。C的malloc函数返回指向分配对象的指针。它只需要一个参数,指定分配对象的大小。而cudaMalloc函数写入作为第一个参数给出的指针变量的地址。因此,cudaMalloc函数需要两个参数。cudaMalloc的这种两参数格式使其能够使用返回值以与其他CUDA API函数相同的方式报告任何错误。
1 | |
一旦主机代码为数据对象在设备全局内存中分配了空间,它可以请求将数据从主机传输到设备。这通过调用CUDA API函数之一来完成。图2.7展示了这样一个API函数,cudaMemcpy。
cudaMemcpy函数有四个参数。
第一个参数是指向要复制的数据对象目标位置的指针。(Pointer to destination)
第二个参数指向源位置。
第三个参数指定要复制的字节数。
第四个参数指示复制涉及的内存类型:从主机到主机,从主机到设备,从设备到主机以及从设备到设备。
例如,内存复制函数可用于将数据从设备全局内存中的一个位置复制到设备全局内存中的另一个位置。
vecAdd函数调用cudaMemcpy函数将A_h和B_h向量从主机内存复制到A_d和B_d在设备内存中,然后将它们相加,并在完成相加后将C_d向量从设备内存复制到C_h在主机内存中。
假设A_h、B_h、A_d、B_d和size的值已经设置好,下面是三个cudaMemcpy调用的示例。cudaMemcpyHostToDevice和cudaMemcpyDeviceToHost是CUDA编程环境中的已识别的预定义常量。请注意,通过正确排序源和目标指针并使用适当的常量进行传输类型,可以使用相同的函数在两个方向上传输数据。
1 | |
总结一下,在图2.4中,主程序调用vecAdd,该函数也在主机上执行。vecAdd函数(见图2.5的概要)在设备全局内存中分配空间,请求数据传输,并调用执行实际矢量加法的核函数。我们将这种主机代码称为用于调用核函数的存根(stub)。
CUDA中的错误检查和处理
通常,对于程序来说,检查并处理错误是很重要的。 CUDA API函数在提供服务时返回指示错误是否发生的标志。大多数错误是由于调用中使用了不适当的参数值。 为简洁起见,我们在示例中不会显示错误检查代码。例如,图2.9中显示了对cudaMalloc的调用:
1 | |
实际上,我们应该将调用包围在测试错误条件的代码中,并打印出错误消息,以便用户能够意识到发生了错误。这样的检查代码的简单版本如下:
1 | |
这样,如果系统没有设备内存,用户将得到关于这种情况的通知。这可以节省许多调试时间。可以定义一个C宏,使源代码中的检查代码更简洁。
2.5 核函数和线程
当程序的主机代码调用核函数时,CUDA运行时系统会启动一个线程网格,该网格组织成两级层次结构。每个网格都组织成一个线程块数组,我们将其简称为块。一个网格中的所有块都是相同大小的;每个块在当前系统上最多可以包含1024个线程。
内建变量
许多编程语言都有内建变量。这些变量具有特殊的含义和目的。这些变量的值通常由运行时系统预初始化,并在程序中通常是只读的。程序员应该避免重新定义这些变量以供其他用途使用。
每个线程块中的总线程数是在调用核函数时由主机代码指定的。同一核函数可以在主机代码的不同部分以不同数量的线程调用。对于给定的线程网格,块中的线程数可以在名为blockDim的内建变量中找到。blockDim变量是一个结构,包含三个无符号整数字段(x、y和z),这些字段帮助程序员将线程组织成一维、二维或三维数组。对于一维组织,仅使用x字段。对于二维组织,使用x和y字段。对于三维结构,使用所有三个x、y和z字段。线程的组织方式通常反映数据的维度。这是有道理的,因为线程是为了并行处理数据而创建的,因此线程的组织方式自然应该反映数据的组织方式。
在图2.9中,每个线程块被组织成一个一维数组的形式,因为数据是一维向量。blockDim.x变量的值表示每个块中的总线程数,在图2.9中为256。通常建议线程块的每个维度的线程数是32的倍数,出于硬件效率的原因。稍后我们将重新讨论这一点。
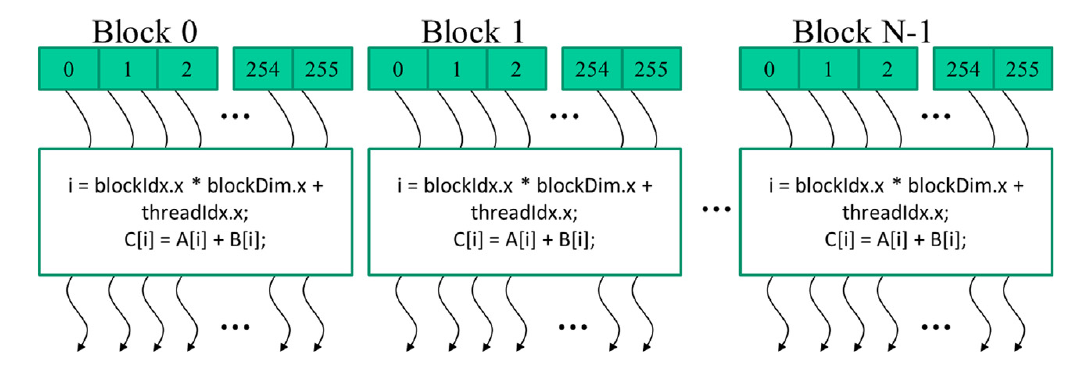
CUDA核函数可以访问另外两个内建变量(threadIdx和blockIdx),这些变量允许线程彼此区分,并确定每个线程要处理的数据区域。threadIdx变量为每个线程提供块内的唯一坐标。在图2.9中,由于我们使用的是一维线程组织,仅使用threadIdx.x。图2.9中每个线程的threadIdx.x值显示在每个线程的小阴影框中。每个块中的第一个线程的threadIdx.x变量的值为0,第二个线程的值为1,第三个线程的值为2,依此类推。
分层组织 与CUDA线程一样,许多实际系统都是分层组织的。美国电话系统就是一个很好的例子。在顶层,电话系统由“区域”组成,每个区域对应一个地理区域。同一区域内的所有电话线都具有相同的3位“区号”。电话区域有时比城市大。例如,伊利诺伊州中部的许多县和城市都属于同一电话区域,并共享相同的区号217。在一个区域内,每条电话线都有一个七位数的本地电话号码,这使得每个区域最多可以拥有约一千万个号码。 可以将每条电话线视为一个CUDA线程,其中区号是blockIdx的值,而七位本地号码是threadIdx的值。这种分层组织允许系统拥有大量的电话线,同时保留对同一区域进行呼叫的“局部性”。也就是说,在拨打同一区域内的电话时,呼叫者只需拨打本地号码。只要我们大多数时间都在本地区域内拨打电话,我们很少需要拨打区号。如果我们偶尔需要拨打另一个区域的电话,我们拨打1和区号,然后是本地号码。 (这就是为什么任何区域的本地号码都不应以1开头的原因。)CUDA线程的分层组织也提供了一种局部性形式。我们将很快研究这种局部性。
在图2.9中,计算了一个唯一的全局索引i,即i=blockIdx.x * blockDim.x + threadIdx.x。回顾一下,我们的示例中blockDim的值为256。块0中线程的i值范围从0到255。块1中线程的i值范围从256到511。块2中线程的i值范围从512到767。也就是说,这三个块中线程的i值形成了从0到767的连续覆盖。由于每个线程使用i来访问A、B和C,这些线程涵盖了原始循环的前768次迭代。通过启动具有更多块的网格,可以处理更大的向量。通过启动具有n个或更多线程的网格,可以处理长度为n的向量。

图2.10显示了一个进行向量相加的核函数。请注意,在核函数中我们不使用“_h”和“_d”约定,因为这里没有潜在的混淆。在我们的示例中,核的语法是ANSI C,并带有一些显著的扩展。首先,在vecAddKernel函数的声明前面有一个CUDA-C特定的关键字“global”。此关键字表示该函数是一个核函数,可以调用它在设备上生成一个线程网格。
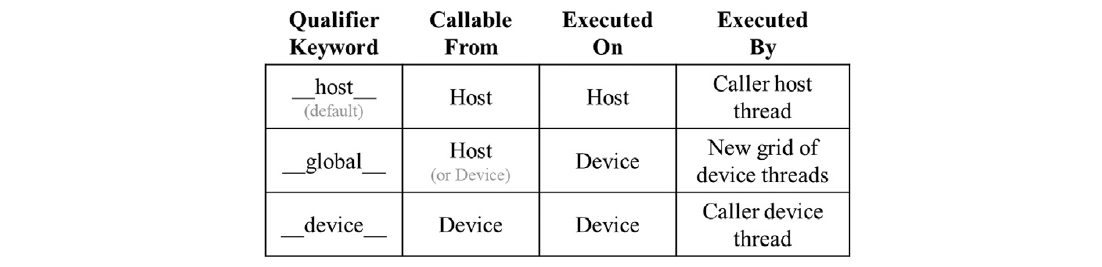
通常,CUDA C使用三个修饰关键字扩展了C语言,这些关键字可以在函数声明中使用。这些关键字的含义总结如图2.11所示。“global”关键字表示被声明的函数是一个CUDA C核函数。请注意,“global”一词两侧都有两个下划线字符。这样的核函数在设备上执行,并且可以从主机调用。在支持动态并行性的CUDA系统中,它也可以从设备调用,我们将在第21章“CUDA动态并行性”中看到。重要的特点是调用这样一个核函数会在设备上启动一个新的线程网格。
“device”关键字表示被声明的函数是CUDA设备函数。设备函数在CUDA设备上执行,只能从核函数或另一个设备函数调用。设备函数由调用它的设备线程执行,不会导致启动任何新的设备线程。7
“host”关键字表示被声明的函数是CUDA主机函数。主机函数只是在主机上执行的传统C函数,只能从另一个主机函数调用。默认情况下,如果在其声明中没有任何CUDA关键字,则CUDA程序中的所有函数都是主机函数。这是有道理的,因为许多CUDA应用程序是从仅CPU执行环境迁移过来的。在迁移过程中,程序员会在主机函数中添加核函数和设备函数。原始函数仍然保留为主机函数。将所有函数默认为主机函数可以免去程序员修改所有原始函数声明的繁琐工作。
请注意,可以在函数声明中同时使用“host”和“device”。这种组合告诉编译系统为同一函数生成两个版本的目标代码。其中一个在主机上执行,只能从主机函数调用。另一个在设备上执行,只能从设备或核函数调用。这支持常见的用例,即相同的函数源代码可以重新编译以生成设备版本。许多用户库函数很可能属于这个类别。
图2.10中有一个自动(局部)变量i。在CUDA核函数中,自动变量对于每个线程都是私有的。也就是说,每个线程都会生成一个i的版本。如果使用10,000个线程启动网格,将会有10,000个版本的i,每个线程一个版本。由线程分配给其i变量的值对其他线程不可见。我们将在第5章“内存架构和数据局部性”中更详细地讨论这些自动变量。
通过将图2.4和图2.10进行快速比较,可以对CUDA核函数有一个重要的了解。图2.10中的核函数没有对应于图2.4中的循环。读者应该问循环去哪了。答案是循环现在被线程网格替代了。整个网格形成了循环的等效部分。网格中的每个线程对应于原始循环的一次迭代。这有时被称为循环并行性,其中原始顺序代码的迭代由线程并行执行。
请注意,图2.10中的addVecKernel函数有一个if (i < n)语句。这是因为并非所有的矢量长度都可以表示为块大小的倍数。例如,假设矢量长度是100。最小的有效线程块维度是32。假设我们选择32作为块大小。将需要启动四个线程块来处理所有100个矢量元素。然而,这四个线程块将有128个线程。我们需要禁用第3个线程块中的最后28个线程,以防它们执行原始程序不期望的工作。由于所有线程都将对它们的i值进行与n的比较,因此所有线程将测试它们的i值是否小于n,其中n是100。通过if (i < n)语句,前100个线程将执行加法,而最后的28个线程将不执行。这允许调用该核函数来处理任意长度的矢量。
- 7 我们将在稍后解释在不同CUDA生成中使用间接函数调用和递归的规则。总的来说,为了实现最大的可移植性,应该避免在设备函数和核函数中使用递归和间接函数调用。
2.6 调用核函数
完成了核函数的实现后,剩下的步骤是从主机代码中调用该函数以启动网格。这在图2.12中进行了说明。当主机代码调用核函数时,它通过执行配置参数设置网格和线程块的维度。配置参数位于传统C函数参数之前的“<<<”和“>>>”之间。第一个配置参数给出了网格中的块数,第二个指定了每个块中的线程数。
在这个例子中,每个块中有256个线程。为了确保我们有足够的线程在网格中覆盖所有的向量元素,我们需要将网格中的块数设置为所需线程数(在这种情况下为n)除以线程块大小(在这种情况下为256)的上取整(将商四舍五入为较高的整数值)。有许多执行上取整的方法。一种方法是对n/256.0应用C天花板函数。使用浮点值256.0确保我们生成一个浮点值,以便天花板函数可以正确地将其上取整。
请注意,所有线程块都在向量的不同部分上操作。它们可以以任意顺序执行。程序员不能对执行顺序做出任何假设。具有较少执行资源的小型GPU可能仅以并行方式执行一个或两个这些线程块。较大的GPU可能并行执行64或128个块。这使得CUDA核函数具有硬件执行速度的可伸缩性。也就是说,相同的代码在小型GPU上以较低的速度运行,在大型GPU上以较高的速度运行。我们将在第4章《计算架构和调度》中重新讨论这一点。
2.7 编译
代码需要由一个能够识别和理解这些扩展的编译器编译,比如NVCC(NVIDIA C编译器)。
2.8 总结
本章提供了CUDA C编程模型的快速、简化概述。CUDA C扩展了C语言以支持并行计算。我们在本章中讨论了这些扩展的基本子集。为方便起见,我们总结了本章中讨论的扩展如下:
2.8.1 函数声明
CUDA C扩展了C函数声明语法,以支持异构并行计算。这些扩展总结在图2.12中。使用“global”、“device”或“host”中的一个,CUDA C程序员可以指示编译器生成内核函数、设备函数或主机函数。所有没有这些关键字的函数声明默认为主机函数。如果在函数声明中同时使用“host”和“device”,编译器将为设备和主机分别生成两个版本的函数。如果函数声明没有任何CUDA C扩展关键字,该函数默认为主机函数。
2.8.2 内核调用和网格启动
CUDA C扩展了C函数调用语法,使用由“<<<”和“>>>”括起的内核执行配置参数。这些执行配置参数仅在调用内核函数以启动网格时使用。我们讨论了定义网格维度和每个块维度的执行配置参数。读者应参阅CUDA编程指南(NVIDIA,2021)以获取有关内核启动扩展以及其他类型执行配置参数的更多详细信息。
2.8.3 内建(预定义)变量
CUDA内核可以访问一组内建的、预定义的只读变量,允许每个线程与其他线程区分开,并确定要处理的数据区域。在本章中,我们讨论了threadIdx、blockDim和blockIdx变量。在第3章“多维网格和数据”中,我们将详细讨论使用这些变量的更多细节。
2.8.4 运行时应用程序编程接口
CUDA支持一组API函数,为CUDA C程序提供服务。我们在本章中讨论的服务是cudaMalloc、cudaFree和cudaMemcpy函数。这些函数由主机代码调用,以代表调用程序分配设备全局内存、释放设备全局内存和在调用程序的代表上在主机和设备之间传输数据。读者请参阅CUDA C编程指南,了解其他CUDA API函数。 我们本章的目标是介绍CUDA C的核心概念以及对C的基本扩展,以编写一个简单的CUDA C程序。该章节绝不是所有CUDA功能的全面介绍。这些功能的一些将在本书的其余部分中进行介绍。然而,我们的重点将放在这些功能支持的关键并行计算概念上。我们将只介绍我们代码示例所需的CUDA C功能,用于并行编程技术。总的来说,我们鼓励读者随时查阅CUDA C编程指南,以获取有关CUDA C功能的更多详细信息。
第三章:多维网格和数据
3.1 多维网格组织
请注意,dimBlock 和 dimGrid 是由程序员定义的主机代码变量。只要它们具有 dim3 类型,它们就可以具有任何合法的 C 变量名。例如,以下语句实现了与上述语句相同的结果:
网格和块的维度也可以从其他变量计算。例如,图2.12中的内核调用可以写成如下形式:

为了方便起见,CUDA 提供了一种特殊的快捷方式,用于调用具有一维(1D)网格和块的内核
熟悉 C++ 的读者会意识到,这种用于 1D 配置的“简写”方便的实现是通过 C++ 构造函数和默认参数的工作方式来实现的。dim3 构造函数的参数的默认值为 1。当在期望 dim3 的地方传递一个单一值时,该值将传递给构造函数的第一个参数,而第二个和第三个参数将采用默认值 1。结果是一个 1D 网格或块,其中 x 维度的大小是传递的值,y 和 z 维度的大小为 1。
在内核函数中,gridDim 和 blockDim 变量的 x 字段根据执行配置参数的值进行了预初始化。例如,如果 n 等于 4000,在 vectAddKernel 内核中对 gridDim.x 和 blockDim.x 的引用将分别得到 16 和 256。请注意,在内核函数中,与主机代码中的 dim3 变量不同,这些变量的名称是 CUDA C 规范的一部分,不能更改。也就是说,gridDim 和 blockDim 是内核中的内置变量,并始终反映网格和块的维度。
在 CUDA C 中,gridDim.x 允许的值范围从 1 到 2^31−1(设备的计算能力低于 3.0 的允许 blockIdx.x 的值在 1 到 216−1 之间 ),gridDim.y 和 gridDim.z 的值范围从 1 到 216−1(65,535)。
在当前的 CUDA 系统中,块的总大小限制为 1024 个线程。这些线程可以以任何方式分布在三个维度上,只要总线程数不超过 1024。例如,(512, 1, 1)、(8, 16, 4) 和 (32, 16, 2) 这样的 blockDim 值都是允许的,但 (32, 32, 2) 不允许,因为总线程数将超过 1024。
网格及其块不需要具有相同的维度。网格的维度可以高于其块,反之亦然。
3.2 将线程映射到多维数据
有至少两种将2D数组线性化的方式。一种方法是将同一行的所有元素放入连续的位置。然后,这些行依次放入内存空间。这种排列称为行主排列
另一种线性化2D数组的方法是将同一列的所有元素放入连续的位置。然后,这些列依次放入内存空间。这种排列称为列主排列,被FORTRAN编译器使用。此外,许多设计用于FORTRAN程序的C库使用列主排列以匹配FORTRAN编译器的排列。因此,这些库的手册通常告诉用户如果从C程序调用这些库,他们应该对输入数组进行转置。

图3.4 colorToGrayscaleConversion的源代码,具有2D线程映射到数据的功能。
3.3 图像模糊:一个更复杂的核
图像模糊可以平滑像素值的突变,同时保留对于识别图像关键特征至关重要的边缘。
在计算机视觉中,图像模糊可以用于使边缘检测和对象识别算法专注于主题对象,而不被大量的细粒度对象拖慢。在显示中,有时通过模糊图像的其余部分来突出显示图像的特定部分。
这些加权总和的计算属于卷积模式。在本章中,我们将采用一种简化的方法,通过对围绕目标像素的N x N像素块进行简单平均值。为了保持算法简单,我们不会根据像素距离目标像素的距离对任何像素的值施加权重。在实践中,对像素值施加权重在卷积模糊方法中是相当常见的,例如高斯模糊。

图3.8 每个输出像素是输入图像中一片周围像素及其自身的平均值
请注意,大多数线程将在其分配的3x3x3像素块中找到所有像素。它们将累加所有九个像素。但是,对于四个角上的像素,负责的线程将只累加四个像素。对于四条边上的其他像素,负责的线程将累加六个像素。这些变化是需要使用变量pixels跟踪实际累积的像素数量的原因。
3.4 矩阵乘法
线性代数函数
线性代数运算在科学和工程应用中被广泛使用。在基本线性代数子程序(BLAS)中,这是一个发布执行基本代数运算的库的事实标准,有三个级别的线性代数函数。随着级别的提高,函数执行的操作数量增加。级别1的函数执行形式为y = αx + y的向量运算,其中x和y是向量,α是标量。我们的向量加法示例是α=1的级别1函数的特例。级别2的函数执行形式为y = αAx + βy的矩阵-向量运算,其中A是矩阵,x和y是向量,α和β是标量。我们将在稀疏线性代数中研究级别2函数的一种形式。级别3的函数执行矩阵-矩阵运算形式为C = αAB + βC,其中A、B和C是矩阵,α和β是标量。我们的矩阵乘法示例是α=1且β=0的级别3函数的特例。这些BLAS函数很重要,因为它们被用作更高级别代数函数的基本构建块,如线性系统求解器和特征值分析。

这些语句几乎与colorToGrayscaleConversion中的相应语句相同。唯一的显著区别是我们做了一个简化假设,即matrixMulKernel只需处理方阵,因此我们用Width替换了宽度和高度。这种线程到数据的映射有效地将P分成了tile,其中一个tile在图3.10中显示为浅色正方形。每个块负责计算其中一个tile。
3.5 总结
CUDA的网格和块是多维的,最多可以有三个维度。网格和块的多维性对于组织线程以映射到多维数据是有用的。核心执行配置参数定义了网格及其块的维度。blockIdx和threadIdx中的唯一坐标允许网格的线程识别自己及其数据域。程序员有责任在核函数中使用这些变量,以便线程能够正确地识别要处理的数据部分。在访问多维数据时,程序员通常需要将多维索引线性化为1D偏移。原因是在C中动态分配的多维数组通常按行主序存储为1D数组。我们使用逐渐复杂的示例使读者熟悉使用多维网格处理多维数组的机制。这些技能将为理解并行模式及其相关的优化技术奠定基础。
第四章:计算架构和调度
4.1 现代GPU的架构
图4.1展示了一个典型有CUDA能力的GPU的架构的高级视图,供CUDA C程序员参考。它组织成一系列高度线程化的流多处理器(SM)。每个SM有多个处理单元,称为流处理器或CUDA核心(SP,以下简称为核心),如图4.1中SM内显示的小块所示,它们共享控制逻辑和内存资源。例如,Ampere A100 GPU具有108个SM,每个SM有64个核心,总共在整个GPU中有6912个核心。
SM还配备了不同的芯片上内存结构,统称为图4.1中的“Memory”。这些芯片上的内存结构将是第5章《内存架构和数据局部性》的主题。GPU还配备了几GB的芯片外设备内存,称为图4.1中的“全局内存”。尽管较早的GPU使用图形双倍数据速率同步DRAM,但更近期的GPU从NVIDIA的Pascal架构开始可能使用HBM(高带宽内存)或HBM2,其中包括与GPU紧密集成在同一封装中的DRAM(动态随机存取存储器)模块。为简便起见,我们将在本书的其余部分广泛地将所有这些类型的内存称为DRAM。我们将在第6章《性能考虑》中讨论访问GPU DRAM的最重要的概念
4.2 块调度
同一块中的所有线程同时分配给同一个SM。图4.2说明了块分配给SM的过程。很可能同时将多个块分配给同一个SM。
由于SM的数量有限以及每个SM可以同时分配的块的数量有限,CUDA设备中可以同时执行的块的总数也有限制。大多数网格包含的块数量远远超过这个数字。为确保执行所有块,运行时系统维护一个需要执行的块的列表,并在先前分配的块完成执行时将新块分配给SM。
线程按块逐块分配给SM的方式确保了同一块中的线程同时在同一个SM上调度。这一保证使得同一块中的线程能够以不同于不同块之间的线程的方式相互交互1。其中包括栅栏同步,将在第4.3节中讨论。这还包括访问位于SM上的低延迟共享内存,将在第5章《内存架构和数据局部性》中讨论。
注1:不同线程块中的线程可以通过合作组(Cooperative Groups) API 进行屏障同步。然而,必须遵守一些重要的限制,以确保所有涉及的线程确实在 SM 上同时执行。

4.3 同步和透明可扩展性
CUDA 允许同一线程块中的线程使用屏障同步函数 __syncthreads() 协调它们的活动。请注意,“”由两个“_”字符组成。__
__当一个线程调用 __syncthreads() 时,它将在调用的程序位置停留,直到同一线程块中的每个线程都到达该位置。这确保了在任何线程继续到下一阶段之前,同一线程块中的所有线程都已完成了它们执行的阶段。
屏障同步是协调并行活动的一种简单而受欢迎的方法。在现实生活中,我们经常使用屏障同步来协调多人的并行活动。例如,假设四个朋友一起去购物中心。他们必须等到所有四个朋友都回到车上,然后才能离开。提前完成的人必须等待那些后完成的人。如果没有屏障同步,当车离开时,可能会有一个或多个人被留在购物中心,这可能会严重损害他们的友谊!

图 4.3 说明了屏障同步的执行过程。线程块中有 N 个线程。时间从左到右流逝。一些线程早早到达屏障同步语句,而一些则迟到得多。早到达屏障的线程将等待那些晚到的线程。当最后一个到达屏障时,所有线程都可以继续执行。有了屏障同步,“没有人会被落下”
在CUDA中,如果存在__syncthreads()语句,则所有线程必须执行该语句。__
__当将__syncthreads()语句放置在if语句中时,该块中的所有线程都要执行包含syncthreads()的路径,或者一个也不执行。
__对于if-then-else语句,如果每个路径都有__syncthreads()语句,则该块中的所有线程都执行then-path或者所有线程都执行else-path。两个syncthreads()是不同的屏障同步点。
__例如,在图4.4中,if语句从第04行开始使用了两个__syncthreads()。所有偶数threadIdx.x值的线程执行then-path,而其余线程执行else-path。在第06行和第10行处的__syncthreads()调用定义了两个不同的屏障。由于不能保证该块中的所有线程都执行任一屏障,该代码违反了使用__syncthreads()的规则,将导致未定义的执行行为。
一般来说,错误的屏障同步使用可能导致不正确的结果,或者线程永远等待对方,这被称为死锁。程序员有责任避免这种不当使用屏障同步。

*图 4.4 __syncthreads()函数的错误使用*
🔍 核心原理:条件决定分支,而非条件内容
关键在于你设定的 “条件表达式”本身,而不是条件的“值”看起来是否均匀(如奇偶)。硬件(具体来说是Warp Scheduler,即 warp 调度器)只看每个线程对条件的计算结果:
- 结果为
true的线程执行if块。 - 结果为
false的线程执行else块(或跳过)。
用你的例子 if (x == 1) 来看,它的效果和
if (threadIdx.x % 2 == 0)
在造成分支的本质上没有任何区别。
- 大胆分支:放心地使用
if-else、switch等让线程根据threadIdx.x等条件执行不同任务。这是CUDA编程的基础模式。 - 小心同步:只有当你的算法需要线程间交换数据(例如,写入后读取共享内存)时,才需要
__syncthreads()。此时,必须确保所有线程无一例外地都会执行到同一个__syncthreads()调用。 - 记住口诀:“分支随意,同步统一”。线程可以分开做事,但必须一起报到。
所以,在你原来的问题中,图4.4代码的错误不在于线程分成了奇偶两个分支,而在于错误地在两个分支里分别放置了屏障,破坏了“一起报到”的规则。
那在if/else的其中一个分支中加入syncthread函数,是不是也不符合规定?
是的,完全不符合规定,这是绝对禁止的错误用法。
这引出了CUDA屏障同步设计中的一个重要权衡。通过不允许不同块中的线程进行屏障同步,CUDA运行时系统可以以任意顺序相对于彼此执行块,因为它们中的任何一个都不需要等待其他块。这种灵活性使得可扩展的实现成为可能
4.4 张量和SIMD硬件
CUDA GPU中的线程调度是硬件实现的概念,因此必须在具体硬件实现的背景下讨论。到目前为止,大多数实现中,一旦一个块被分配到一个SM,它会进一步划分为32个线程单元,称为warp
- warp是SM中线程调度的单元。
在这个例子中,有三个块—块1、块2和块3—都分配给一个SM。每个块都被进一步划分为warp以进行调度。每个warp由32个连续的threadIdx值组成:线程0到31组成第一个warp,线程32到63组成第二个warp,依此类推。我们可以计算出在给定的块大小和每个SM分配的块数的情况下,驻留在SM中的warp的数量。
SM的设计是为了按照单指令多数据(SIMD)模型执行warp中的所有线程。也就是说,在任何时刻,为warp中的所有线程提取和执行一条指令(请参阅“Warps and SIMD Hardware”侧栏)。图4.8显示了SM中的核心如何分组成处理块,其中每8个核心形成一个处理块,并共享一台指令提取/调度单元。例如,Ampere A100 SM有64个核心,组织成四个每个16个核心的处理块。同一warp中的线程被分配到相同的处理块,该块为warp提取指令,并同时为warp中的所有线程执行它。这些线程将相同的指令应用于数据的不同部分。由于SIMD硬件有效地限制了warp中的所有线程在任何时间点执行相同的指令,warp的执行行为通常被称为单指令,多线程。

Warps and SIMD Hardware
在他1945年的开创性报告中,约翰·冯·诺伊曼描述了一种构建电子计算机的模型,该模型基于先驱性的EDVAC计算机的设计。这个模型,现在通常被称为“冯·诺伊曼模型”,已经成为几乎所有现代计算机的基础蓝图。

程序由一系列指令组成。控制单元维护一个程序计数器(PC),其中包含要执行的下一条指令的内存地址。在每个“指令周期”中,控制单元使用PC将指令提取到指令寄存器(IR)中。然后,检查指令的位以确定计算机的所有组件需要执行的操作。这也是该模型被称为“存储程序”模型的原因,这意味着用户可以通过将不同的程序存储到计算机的内存中来更改计算机的行为。
在以下修改的冯·诺伊曼模型中,以适应GPU设计,说明了将线程作为warp执行的动机

由于所有处理单元都由控制单元的指令寄存器(IR)控制,它们的执行差异是由寄存器文件中不同的数据操作数值引起的。这在处理器设计中被称为单指令多数据(SIMD)。例如,尽管所有处理单元(核心)都由一条指令控制,例如add r1, r2, r3,但r2和r3的内容在不同的处理单元中是不同的。
现代处理器的控制单元非常复杂,包括用于提取指令的复杂逻辑和用于指令高速缓存的访问端口。让多个处理单元共享一个控制单元可以显著减少硬件制造成本和功耗。
4.5 控制分支
当warp中的所有线程在处理数据时都遵循相同的执行路径(更正式地称为控制流)时,SIMD执行效果很好。例如,对于if-else结构,当warp中的所有线程执行if-path或全部执行else-path时,执行效果很好。然而,当warp中的线程采用不同的控制流路径时,SIMD硬件将对这些路径进行多次遍历,每个路径一次。例如,对于if-else结构,如果warp中的一些线程遵循if-path而另一些线程遵循else-path,硬件将执行两次。一次执行遵循if-path的线程,另一次执行遵循else-path的线程。在每次遍历期间,遵循另一路径的线程将不被允许产生效果。
当同一warp中的线程遵循不同的执行路径时,我们说这些线程表现出控制分支,即它们在执行中分岔。分支warp执行的多通道方法扩展了SIMD硬件实现CUDA线程的完整语义的能力。虽然硬件对warp中的所有线程执行相同的指令,但它有选择地只让这些线程在对应于它们所采取的路径的通道中产生效果,从而使每个线程都可以似乎采取自己的控制流路径。这保留了线程的独立性,同时利用了SIMD硬件的降低成本。然而,分支的代价是硬件需要执行额外的通道,以允许warp中的不同线程做出自己的决策,以及每个通道中由非活动线程消耗的执行资源。

图4.9显示了warp如何执行分支的if-else语句的示例。在这个例子中,当由线程0到31组成的warp到达if-else语句时,线程0到23走then-path,而线程24到31走else-path。在这种情况下,warp将通过代码执行一次,其中线程0到23执行A,而线程24到31处于非活动状态。warp还将通过代码执行另一次,其中线程24到31执行B,而线程0到23处于非活动状态。然后,warp中的线程重新汇聚并执行C。在Pascal架构和之前的架构中,这些通道是按顺序执行的,意味着一次通道执行完毕后另一次通道执行。
从Volta架构开始,这些通道可以并发执行,意味着一次通道的执行可能与另一次通道的执行交错进行。这个特性被称为独立线程调度。有兴趣的读者可以参考Volta V100架构的白皮书(NVIDIA,2017)了解详细信息。
此处关键要理解 “inactive”:在硬件执行某个分支时,有一部分线程也参与,但它的结果不被接受,这就是 “没有被激活” (活跃状态)

图4.10 warp在for循环中分支的示例。
分支也可能在其他控制流结构中出现。图4.10展示了warp如何执行分支的for循环的示例。在这个例子中,每个线程执行不同数量的循环迭代,循环迭代的数量在四和八之间变化。在前四次迭代中,所有线程都是活动的并执行A。在剩余的迭代中,一些线程执行A,而其他线程因为已经完成它们的迭代而不活动。
在处理线程映射到数据时,使用具有线程控制分支的控制结构的一个普遍原因是处理边界条件。这通常是因为线程的总数需要是线程块大小的倍数,而数据的大小可以是任意的数字。例如,在第2章的矢量加法kernel中,我们在addVecKernel中有一个if(i < n)语句。这是因为不是所有的矢量长度都可以表示为块大小的倍数。例如,假设矢量长度为1003,我们选择64作为块大小。需要启动16个线程块来处理所有1003个矢量元素。然而,这16个线程块将有1024个线程。我们需要禁用线程块15中的最后21个线程,以防止它们执行原始程序不期望或不允许的工作。请记住,这16个块被分成32个warps。只有最后一个warp(即最后一个块中的第二个warp)会有控制分支。
请注意,控制分支的性能影响会随着正在处理的矢量大小的增加而减小。
再次强调,控制分支的性能影响会随着水平尺寸中像素数量的增加而减小。例如,如果我们使用16 × 16块处理一个200 × 150的图片,将会有总共130个块(13 × 10块)或1040个warps。区域1到4中的warps的数量将分别为864个(12 × 9 × 8)、72个(9 × 8)、96个(12 × 8)和8个(1 × 8)。其中只有80个warps会有控制分支。因此,控制分支的性能影响将小于8%。显然,如果我们处理一个在水平尺寸上有超过1000个像素的真实图片,控制分支的性能影响将小于2%。
控制分支的一个重要含义是不能假设warp中的所有线程具有相同的执行时序。因此,如果warp中的所有线程必须在任何一个线程继续之前完成其执行阶段,必须使用类似于__syncwarp()的屏障同步机制来确保正确性。
4.6 Warp调度和延迟容忍
当线程分配给SM时,通常分配给SM的线程比SM中的核心多。也就是说,每个SM只有足够的执行单元在任何时刻执行分配给它的所有线程的子集。
一个合理的问题是,如果它在任何时刻只能执行它们的一个子集,为什么我们需要给一个SM分配这么多的warp?答案是这是GPU容忍长延迟操作(如全局内存访问)的方式。
当一个warp要执行的指令需要等待先前启动的长延迟操作的结果时,该warp不会被选中执行。相反,将选择另一个不再等待先前指令结果的常驻warp进行执行。如果有多个warp准备执行,将使用优先机制选择一个进行执行。
从某些线程的操作的延迟时间中填充其他线程的工作的这种机制通常称为“延迟容忍”或“隐藏延迟”(见“延迟容忍”侧边栏)。
有了足够的warp,硬件很可能在任何时刻找到一个要执行的warp,从而在一些warp的指令等待这些长延迟操作的结果时充分利用执行硬件。准备执行的warp的选择不会在执行时间轴上引入任何空闲或浪费时间,这被称为零开销线程调度(见“线程、上下文切换和零开销调度”侧边栏)。
通过warp调度,warp指令的长等待时间被其他warp的指令执行“隐藏”起来。容忍长操作延迟的能力是GPU不像CPU那样将几乎所有芯片面积用于缓存内存和分支预测机制的主要原因。因此,GPU可以将更多的芯片面积用于浮点执行和内存访问通道资源。
线程、上下文切换和零开销调度
基于冯·诺依曼模型,我们准备更深入地了解线程是如何实现的。在现代计算机中,线程是在冯·诺依曼处理器上执行程序的程序和状态。回顾一下,线程包含程序代码、正在执行的代码中的指令以及其变量和数据结构的值。
在基于冯·诺依曼模型的计算机中,程序的代码存储在内存中。PC跟踪正在执行的程序指令的地址。IR保存正在执行的指令。寄存器和内存保存变量和数据结构的值。
现代处理器被设计为允许上下文切换,其中多个线程可以通过轮流取得进展来共享处理器。通过仔细保存和恢复PC值以及寄存器和内存的内容,我们可以暂停线程的执行并正确地稍后恢复线程的执行。然而,在这些处理器中,在上下文切换期间保存和恢复寄存器内容可能会带来显着的执行时间开销。
零开销调度是指GPU能够使需要等待长延迟指令结果的warp进入休眠状态,并激活一个准备就绪的warp,而不会在处理单元中引入任何额外的空闲周期。传统的CPU会因为从一个线程切换到另一个线程需要将执行状态(如传出线程的寄存器内容)保存到内存并从内存加载传入线程的执行状态而产生这样的空闲周期。GPU SM通过在硬件寄存器中保存所有已分配warp的执行状态来实现零开销调度,因此在从一个warp切换到另一个warp时不需要保存和恢复状态。
为了使延迟容忍有效,希望一个SM分配给它的线程数量要比其执行资源同时支持的线程数量多得多,以最大化在任何时刻找到准备执行的warp的机会。例如,在Ampere A100 GPU中,一个SM有64个核心,但可以同时分配给它最多2048个线程。因此,SM可以同时分配给它的线程数量最多比其核心在任何给定时钟周期支持的数量多32倍。对SM的线程进行过量分配是延迟容忍的关键。当当前执行的warp遇到长延迟操作时,它增加了找到另一个准备执行的warp的机会。
这段文字让我知道了GPU相比CPU的强大延迟隐藏能力,但是我没理解为什么同样的操作GPU可以做到零延迟而cpu却不行,给我讲解清楚
这是一个非常深刻的问题。你已经抓住了 GPU 架构设计的灵魂:“用空间换取时间,用并行掩盖延迟”。
要理解为什么 GPU 能做到“零开销(Zero-overhead)”而 CPU 不行,核心在于硬件资源的分配方式方式。我们可以从以下三个维度来拆解:
1. 寄存器状态的“常驻”与“交换”
这是最根本的区别。
CPU 的做法(上下文切换):
CPU 的核心通常只有一套(或很少几套)通用的寄存器组(Register File)。当 CPU 要从线程 A 切换到 线程 B 时,硬件必须执行“保存和恢复”操作:
把线程 A 当前寄存器里的所有值存到内存(或者 Cache)里。
把线程 B 之前存放在内存里的值重新加载到寄存器的硬件电路中。
这个过程需要消耗大量的时钟周期(通常是几百个到上千个),这也就是所谓的“上下文切换开销”。
GPU 的做法(硬件常驻):
GPU 的流式多处理器(SM)拥有极其巨大的寄存器文件(Register File)。当一个 Kernel 启动时,GPU 会根据线程所需寄存器的数量,为每一个 Warp 预先分配好专属的硬件寄存器空间。
- 关键点: 只要这个 Warp 还在运行(Active),它的所有变量、PC(程序计数器)和状态都一直留在硬件寄存器里,不需要搬运到内存。
- 切换过程: 调度器只需要在时钟周期里切换一下“当前的激活指针”,指向另一组已经准备好的硬件寄存器。这就像是从看一张卷子切换到看另一张卷子,卷子都在桌面上,不需要从书包里掏出来。
2. 调度机制:硬件逻辑 vs 操作系统
CPU 调度(OS 介入):
CPU 的线程切换通常涉及到操作系统内核(Kernel)的干预。操作系统需要根据优先级、时间片等算法来决定谁运行。这种“决策”本身就是复杂的软件逻辑,非常重。
GPU 调度(纯硬件 Scoreboard):
GPU SM 内部有一个硬件调度单元(Warp Scheduler)。它通过一种叫做 记分板(Scoreboard) 的硬件机制,每时钟周期检查所有 Warp 的状态:
Warp 1:正在等内存数据(阻塞)。
Warp 2:正在等浮点运算结果(阻塞)。
Warp 3:指令已就绪(Ready)。
调度器会在 1 个时钟周期内 直接挑选出 Warp 3 并发射指令。因为状态全在硬件里,这种“挑选”几乎是瞬时的,没有任何指令周期的浪费。
4. 为什么 CPU 不能学 GPU 这样设计?
你可能会问:既然零延迟这么好,为什么 CPU 不把寄存器做大一点,让所有线程都常驻?
- 芯片面积与成本: 寄存器是非常昂贵的硬件资源(SRAM 结构,占用面积大且耗电)。CPU 追求的是单线程的最快速度。如果把面积全给了寄存器,就没地方放巨大的 L3 Cache 和复杂的分支预测器了,那单线程性能会暴跌。
- 不同的优化目标: * CPU 减少延迟:
通过 Cache 和分支预测,尽量让延迟不发生。
- GPU 容忍延迟: 承认延迟很高(访问显存要几百个周期),但通过极大规模的并行,保证总是有活干,从而让整体吞吐量(Throughput)最大化。
CPU试图通过复杂的预测和缓存来“避免”或“缩短”延迟。而GPU通过海量的线程直接“无视”和“填满”延迟。
总结
GPU 所谓的“零开销”,是因为它在硬件层面静态分配了资源。每一个活跃的线程都在硬件里占着坑位,切换只是“目光的移动”,而不是“物资的搬运”。
既然你现在正在学习 CUDA 编程,你是否想过:如果一个 Kernel 函数里定义的局部变量特别多,会如何影响这种“零开销”的调度能力?(这涉及到 Occupancy 占用率的概念,是性能优化的核心)
4.7 资源划分和占用
我们已经看到,为了容忍长延迟操作,将许多warp分配给一个SM是可取的。然而,并不总是可能将SM支持的最大数量的warp分配给SM。分配给SM的warp数量与其支持的最大数量之比被称为占用率(Occupancy )。要了解阻止SM达到最大占用率的原因,首先要了解SM资源是如何划分的。
SM中的执行资源包括寄存器、共享内存(在第5章“内存体系结构和数据局部性”中讨论)、线程块槽(thread block slots)和线程槽(thread slots)。这些资源在线程之间动态划分,以支持它们的执行。例如,Ampere A100 GPU最多可以支持每个SM 32个块,64个warp(2048个线程)和每个块1024个线程。如果以1024个线程的块大小(最大允许的大小)启动网格,则每个SM中的2048个线程槽将被划分并分配给2个块。在这种情况下,每个SM最多可以容纳2个块。类似地,如果以512、256、128或64个线程的块大小启动网格,2048个线程槽将被划分并分配给4、8、16或32个块。
在块之间动态划分线程槽的能力使得SM变得多才多艺。它们可以执行许多每个具有少量线程的块,也可以执行少量每个具有许多线程的块。这种动态划分与固定划分方法形成对比,固定划分方法中,每个块将收到一定量的资源,而不考虑其实际需求。当块需要的线程少于固定划分支持的线程时,固定划分会导致线程槽浪费,而且无法支持需要更多线程槽的块。
另一种可能对占用率产生负面影响的情况是,SM的最大线程数不能被块(Block)大小整除。在Ampere A100的例子中,我们看到每个SM最多可以支持2048个线程。然而,如果选择块大小为768,SM将只能容纳2个线程块(1536个线程),剩下512个线程槽未使用。在这种情况下,既未达到SM每个块的最大线程数,也未达到SM每个块的最大数量。在这种情况下,占用率为(分配的1536个线程)/(最大2048个线程)= 75%。
这引出了 CUDA 编程的一个重要经验法则
为了获得 100% 的占用率(Occupancy),我们通常会选择 2 的幂次方 或者 Warp 大小(32)的倍数 来作为 Block Size。
常见的推荐值包括:
- 128, 256, 512:这些数字通常能完美整除 2048。
- 比如选择 256:2048/256 = 8。SM 可以正好放下 8 个完整的 Block,占用率 100%。
- 比如选择 512:2048/512 = 4。SM 可以正好放下 4 个完整的 Block,占用率 100%。
前面的讨论没有考虑其他资源约束的影响,例如寄存器和共享内存。在第5章“内存体系结构和数据局部性”中,我们将看到在CUDA内核中声明的自动变量存储在寄存器中。一些内核可能使用许多自动变量,而其他内核可能使用较少的自动变量。因此,应该预期一些内核每个线程需要许多寄存器,而其他内核每个线程需要较少的寄存器。通过在SM中动态划分寄存器,SM可以容纳许多块,如果它们每个线程需要较少的寄存器,以及如果它们每个线程需要更多的寄存器,则需要较少的块。
读者应该清楚的是,所有动态划分的资源的约束以复杂的方式相互作用。准确确定每个SM中运行的线程数可能是困难的。读者可以参考CUDA占用率计算器(CUDA占用率计算器,网上下载,),这是一个可下载的电子表格,根据内核对资源的使用,计算给定设备实现上每个SM上实际运行的线程数。
【译注:请使用https://docs.nvidia.com/nsight-compute/NsightCompute/index.html#occupancy-calculator】
4.8 查询设备属性
我们关于SM资源划分的讨论引发了一个重要问题:我们如何找出特定设备可用的资源量?当CUDA应用程序在系统上执行时,如何查找设备中的SM数量以及每个SM可以分配的块和线程数量?
资源和能力查询
每个CUDA设备SM中的资源量是设备的计算能力的一部分。一般而言,计算能力水平越高,每个SM中的资源就越多。 GPU的计算能力往往会从一代到下一代逐渐增加。 Ampere A100 GPU的计算能力为8.0。
在CUDA C中,有一种内置机制,使主机代码能够查询系统中可用设备的属性。CUDA运行时系统(设备驱动程序)具有一个名为cudaGetDeviceCount的API函数,该函数返回系统中可用的CUDA设备数量。主机代码可以通过使用以下语句找出可用的CUDA设备数量:
1 | |
虽然可能不太明显,但现代PC系统通常具有两个或更多的CUDA设备。这是因为许多PC系统配备了一个或多个“集成”GPU。这些GPU是默认的图形单元,并提供基本的功能和硬件资源,以执行现代窗口化用户界面的最低图形功能。大多数CUDA应用程序在这些集成设备上的性能不会很好。这将是主机代码迭代遍历所有可用设备,查询其资源和能力,并选择那些具有足够资源以满足应用程序性能的设备的原因。
CUDA运行时将系统中所有可用的设备编号从0到devCount-1。它提供了一个名为cudaGetDeviceProperties的API函数,该函数返回给定数字的设备的属性。例如,我们可以在主机代码中使用以下语句迭代可用设备并查询其属性:
1 | |
内置类型cudaDeviceProp是一个C结构类型,其字段表示CUDA设备的属性。读者可以参考CUDA C编程指南,了解该类型的所有字段。我们将讨论一些特别与分配执行资源给线程相关的字段。我们假设属性在由cudaGetDeviceProperties函数设置的devProp变量中返回。
设备中的SM数量在devProp.multiProcessorCount中给出。
主机代码可以在字段devProp.maxThreadsDim[0](x维度),devProp.maxThreadsDim[1](y维度)和devProp.maxThreadsDim[2](z维度)中找到每个块的每个维度上允许的最大线程数。使用此信息的一个示例是对于自动调整系统,在评估底层硬件的最佳性能块尺寸时设置块维度的范围。类似地,它可以在devProp.maxGridSize[0](x维度),devProp.maxGridSize[1](y维度)和devProp.maxGridSize[2](z维度)中找到网格的每个维度上允许的最大块数。此信息的典型用途是确定网格是否可以具有足够的线程来处理整个数据集,或者是否需要某种迭代方法。
字段devProp.regsPerBlock给出了每个SM中可用的寄存器数量。此字段对于确定内核是否可以在特定设备上实现最大占用或是否将受到其寄存器使用的限制非常有用。请注意,字段的名称有点误导人。对于大多数计算能力级别,块可以使用的寄存器的最大数量确实与SM上可用的总寄存器数量相同。但是,对于某些计算能力级别,块可以使用的寄存器的最大数量小于SM上可用的总寄存器数量。
我们还讨论了warp的大小取决于硬件。 warp的大小可以从devProp.warpSize字段中获得。
cudaDeviceProp类型中还有许多其他字段。随着我们介绍它们设计来反映的概念和特性,我们将在整本书中讨论它们。
在 CUDA 的世界里,CUDA 运行时系统(CUDA Runtime) 就像是一个“高级管家”。
最直观的理解方式是:它是介于你的代码与显卡驱动之间的一个软件抽象层。
1. 它处于什么位置?
为了看清它的本质,我们可以看看 CUDA 的软件栈层次:
- 应用层:你写的
.cu代码。 - CUDA Runtime API(也就是你问的):以
cuda开头的函数(如cudaMalloc,cudaMemcpy,cudaLaunchKernel)。它是为了让程序员用起来更爽而设计的。 - CUDA Driver API:更底层的接口,函数以
cu开头(如cuMemAlloc)。它直接跟显卡驱动打交道,极其繁琐,需要手动管理上下文(Context)和模块加载。 - 显卡驱动 (Driver):直接控制硬件。
2. 它到底负责“运行”什么?
“运行时”之所以叫运行时,是因为它在你的程序运行期间默默做了很多自动化工作。如果没有它,你需要手动写几百行代码才能让 GPU 动起来。它的核心任务包括:
A. 隐式上下文管理 (Implicit Context Management)
在底层(Driver 层面),GPU 运行需要创建一个“上下文”。
- 没有 Runtime: 你必须手动初始化设备、创建上下文、销毁上下文。
- 有了 Runtime: 在你第一次调用 CUDA 函数(比如
cudaMalloc)时,它会自动帮你完成初始化。
B. 内存管理与映射
它负责在 CPU 和 GPU 之间建立沟通桥梁。当你调用
cudaMalloc 时,Runtime
会与操作系统和驱动协作,在显存里划出一块空间,并返回一个指针。
C. 核函数发射 (Kernel Launch)
当你写 kernel<<<grid, block>>>()
时,这不是标准 C++ 语法。CUDA 编译器(NVCC)会把这段语法转换成 Runtime
API 的调用。Runtime 负责:
- 把参数打包。
- 配置 Grid 和 Block。
- 把任务推送到 GPU 的硬件队列里。
D. 错误处理与设备同步
它维护着每个线程的错误状态。你可以通过
cudaGetLastError()
询问这个管家:“刚才那个核函数执行成功了吗?”
3. 为什么会有这个名词?
在计算机科学中,“Runtime” 通常指一个程序运行所必须的支持环境(比如 Java 有 JVM,C# 有 .NET Runtime)。
CUDA Runtime 的存在,就是为了隐藏 GPU 硬件操作的底层复杂性。 由于你熟悉 Linux 和 C++,你可以把它类比为标准库 libc。你调用 printf 时,不需要知道 Linux 内核是如何操作显存像素或串口的,libc 这个运行时库帮你搞定了系统调用。CUDA Runtime 也是同理,它帮你搞定了复杂的显卡驱动调用
4.9 总结
GPU被组织成SM,它包含多个核心的处理块,这些核心共享控制逻辑和内存资源。当启动一个网格时,其块以任意顺序分配给SM,从而实现CUDA应用程序的透明可伸缩性。透明可伸缩性伴随着一个限制:不同块中的线程无法相互同步。
线程按块为单位分配给SM进行执行。一旦块分配给了SM,它进一步分为warp。warp中的线程按照SIMD模型执行。如果同一warp中的线程通过采取不同的执行路径而分支,处理块将按照每个线程仅在其所采取的路径对应的通行中处于活动状态的顺序执行这些路径。
一个SM可能分配给它的线程比它可以同时执行的线程多得多。在任何时候,SM只执行其驻留warp的一个小子集的指令。这使得其他warp可以等待长延迟操作,而不减缓庞大数量的处理单元的整体执行吞吐量。分配给SM的线程数与其支持的最大线程数之比称为占用率。 SM的占用率越高,它越能有效地隐藏长延迟操作。
每个CUDA设备对每个SM中可用资源的限制可能是不同的。例如,每个CUDA设备都对其SM可以容纳的块数、线程数、寄存器数和其他资源的数量有限制。对于每个内核,这些资源限制中的一个或多个可能成为占用的限制因素。CUDA C提供了在运行时查询GPU中可用资源的能力。
每个SM中也会分块,这些块叫什么?它们中可以装载多个block对吗?为什么要再分块
你观察得非常细致。在 NVIDIA GPU 的硬件架构中,SM 内部确实会进一步划分,这些更小的单元被称为 处理块(Processing Blocks),在官方文档(如 Ampere 或 Hopper 架构)中,它们通常被称为 Sub-partitions 或 SMSP (SM Sub-Partitions)。
通常一个 SM 会被划分为 4 个 Sub-partitions。
1. 它们中可以装载多个 Block 吗?
答案是:可以,但它们与 Block 的关系不是“包含”,而是“分配”。
- SM 层面:Block 是在 SM 层面进行资源申请的(寄存器、共享内存)。一个 SM 可以同时驻留多个 Block。
- Sub-partition 层面:当一个 Block 进入 SM 后,它的 Warp 会被分发到这 4 个 Sub-partition 中去执行。
- 分配逻辑:如果一个 Block 有 128 个线程(4 个 Warp),由于 SM 有 4 个 Sub-partition,硬件可能会给每个 Sub-partition 分配这个 Block 中的 1 个 Warp。如果 SM 里有多个 Block,它们的 Warp 会交错地分布在这些 Sub-partition 中。
2. 为什么要再分块(Sub-partition)?
这种“SM 内部再分块”的设计主要是为了解决管理效率和硬件复杂度的平衡。
A. 简化硬件调度(分而治之)
如果 1 个 SM 要同时调度 2048 个线程(64 个 Warp),让一个调度器同时盯着 64 个 Warp 看谁准备好了,电路逻辑会非常复杂且耗电。
通过分块,每个 Sub-partition 只需要负责 1/4 的 Warp 调度(比如 16 个)。每个子块有自己独立的:
- Warp Scheduler(Warp 调度器)
- Instruction Dispatch Unit(指令分发单元)
- Register File(寄存器堆的一块碎片)
B. 提高资源利用率(计算单元配比)
GPU 内部有不同种类的计算单元(计算核心):
- FP32:普通的浮点运算。
- INT32:整数运算。
- Tensor Core:AI 矩阵运算。
- SFU:特殊函数单元(算 sin、log 等)。
如果所有 Warp 都挤在一起抢这些单元,会造成严重的排队。分块后,每个 Sub-partition 拥有一套固定的计算单元比例。这样可以实现并行的指令发射——4 个子块可以在同一个时钟周期内,各自发射一条指令,从而实现极高的吞吐量。
C. 数据局部性与能效
寄存器堆非常大。如果所有计算单元都要访问同一个巨大的寄存器堆,走线会非常长,延迟和功耗都很高。分块后,计算单元离它负责的那部分寄存器更近,物理结构上更优化。
3. 一个直观的对比
| 层次 | 职责 | 资源 |
|---|---|---|
| SM | 资源管家 | 管理 Shared Memory,决定 Block 能不能进来。 |
| Sub-partition | 前线指挥官 | 管理自己的 Warp 调度器,决定下一拍执行哪条指令。 |
总结
你看到的“分块”其实是硬件上的 “分片管理”。作为软件开发者,你通常只需要关注 Block 层面,但了解 Sub-partition 能够帮你理解为什么 Warp 是 32 个线程(因为子块的发射宽度和寄存器访问通常是以 Warp 为单位优化的)。
既然你已经了解到 SM 内部的子块结构了,你想看看在具体的 A100 架构图中,这些子块是如何共享 L1 Cache 和 Shared Memory 的吗?
第五章:内存架构和数据局部性
在本章中,我们将专注于GPU的片上内存架构,并开始研究如何组织和定位数据,以便大量线程高效访问。
5.1 内存访问效率的重要性
我们可以通过计算图3.11中最常执行的矩阵乘法核心代码的预期性能水平来说明内存访问效率的影响,该代码在图5.1中部分复制。就执行时间而言,核心的最重要部分是执行 M 行与 N 列的点积的 for 循环。
在循环的每次迭代中,为了一个浮点乘法和一个浮点加法,会执行两次全局内存访问。
我们将受内存带宽限制的程序的执行速度称为内存密集型(bound)程序。
屋顶线(Roofline)模型
屋顶线模型是一种用于评估应用程序相对于其运行硬件极限所实现性能的视觉模型。下面是屋顶线模型的一个基本示例。

在x轴上,我们有以FLOP/B为单位的算术或计算强度。它反映了应用程序为每个加载的字节数据所执行的工作量。在y轴上,我们有以GFLOPS为单位的计算吞吐量。图中的两条线反映了硬件的限制。
- 水平线由硬件可以维持的峰值计算吞吐量(GFLOPS)确定。
- 从原点开始的带有正斜率的线由硬件可以维持的峰值内存带宽确定。
图中的一个点代表了一个应用程序,其操作强度在x轴上,其在y轴上实现的计算吞吐量。当然,这些点将位于两条线的下方,因为它们不能实现比硬件峰值更高的吞吐量。
点相对于这两条线的位置告诉我们有关应用程序效率的信息。靠近这两条线的点表明应用程序有效地使用了内存带宽或计算单元,而远离这两条线的应用程序表示资源使用不足。这两条线的交点表示应用程序从内存密集型转换为计算密集型的计算强度值。
- 计算强度较低的应用程序是内存密集型的,并且无法实现峰值吞吐量,因为它们受到内存带宽的限制。
- 计算强度较高的应用程序是计算密集型的,并且不受内存带宽的限制。
举例来说,点 A1 和 A2 都代表内存密集型应用程序,而 A3 代表计算密集型应用程序。A1有效地利用资源,并且接近峰值内存带宽,而 A2 则没有。对于A2,可能有进一步优化的空间,以通过改善内存带宽利用率来提高吞吐量。然而,对于A1,提高吞吐量的唯一方法是增加应用程序的计算强度。
要提高此核心的性能,我们需要通过减少它执行的全局内存访问次数来提高核心的计算与全局内存访问比率。例如,为了充分利用A100 GPU提供的 19,500 GFLOPS,至少需要(19,500 GOP/秒)/(1555 GB/秒)=12.5 OP/B的比率。这个比率意味着,对于每个访问的 4 字节浮点值,必须执行大约 50 次浮点操作!这种比率能够达到的程度取决于正在进行的计算中固有的数据重用。我们建议读者阅读“屋顶线模型”旁注,以了解有关使用计算强度分析程序潜在性能的有用模型。
正如我们将看到的,矩阵乘法提供了减少全局内存访问的机会,这可以通过相对简单的技术来捕获。矩阵乘法函数的执行速度可以根据全局内存访问的减少程度而相差几个数量级。因此,矩阵乘法为这些技术提供了一个极好的初始示例。本章介绍了一种常用的减少全局内存访问次数的技术,并在矩阵乘法上演示了该技术。
别担心,Roofline(屋顶线)模型刚接触时确实容易让人头晕,因为它把硬件的物理极限和软件的代码逻辑强行画在了同一张图上。
为了让你不再晕,我们把这个模型拆解成一个“厨师与食材”的故事。
1. 核心矛盾:厨师快,还是快递快?
想象你在开一家快餐店:
- 厨师(GPU 计算核心):炒菜速度极快,每秒能炒 100 份菜(这是 峰值计算能力)。
- 快递员(内存带宽):负责从仓库把食材运到厨房。如果路很远,每秒只能运 10 斤肉(这是 峰值内存带宽)。
Roofline 模型就是为了回答一个问题:你的店出菜慢,是因为厨师手速到极限了?还是因为食材供不应求?
2. 坐标轴:你在干什么活?
- X 轴:计算强度(Arithmetic Intensity)
- 单位:FLOP/Byte(次计算/字节)。
- 意思:“每领一斤肉,你要炒几个菜?”
- 如果只是把肉洗洗就装盘(数据搬运),计算强度极低;如果要雕花、腌制、各种复杂工序(复杂的数学运算),计算强度就高。
- Y 轴:计算吞吐量(Performance)
- 单位:GFLOPS(每秒完成多少次浮点运算)。
- 意思:“你最后每秒实际上出了多少道菜?”
3. 那条“屋顶线”是怎么来的?
屋顶是由两根线组成的:
第一根:斜线(内存带宽的限制)
在 X 轴数值很小的时候(你每拿一个数据只做很少的计算),你出菜的速度完全取决于快递员送货的速度。
- 公式:Attainable_Performance = 计算强度 × 内存带宽。
- 这就是那条斜线,代表:“巧妇难为无米之需”。这时候你处于 Memory-Bound(内存受限)。
第二根:水平线(计算能力的限制)
当你每拿一斤肉都要雕花三个小时(计算强度极大),快递员送货再快也没用了,因为厨师忙不过来。
- 公式:Attainable_Performance = 硬件峰值计算能力。
- 这就是那条平线,代表:“厨师已经抡出火星子了”。这时候你处于 Compute-Bound(计算受限)。
4. 那个神秘的“12.5 OP/B”是什么意思?
这是整个模型的灵魂关键点:拐点(Ridge Point)。
以你提到的 A100 为例:
- 计算峰值:19, 500 GFLOPS
- 带宽峰值:1, 555 GB/s
- 拐点 = 19500/1555 ≈ 12.5 FLOP/Byte。
这意味着:
- 如果你的代码计算强度 < 12.5:你永远跑不到 19,500 的高速度,因为内存喂不饱计算核心。你无论怎么优化计算指令都没用,你得优化内存访问(比如用 Shared Memory)。
- 如果你的代码计算强度 > 12.5:你才有可能摸到 19,500 的天花板。
5. 举个例子:矩阵乘法
你之前做过 TinyCUDA-BLAS
的矩阵乘法优化,我们可以用这个模型来复盘:
- 最简单的实现:每个线程从显存读两个数,做一个乘加,再写回去。计算强度极低,你会被压在斜线上,GPU 大部分时间在等数据。
- 加入 Cache Blocking / Shared Memory:你把数据读进片上高速缓存,然后重复利用它几百次。划重点: 你并没有改变硬件,但你通过“重用数据”,把你的程序在 X 轴上向右推了。
- 结果:你的程序从“内存受限”变成了“计算受限”,最终贴近了那条水平的屋顶线。
总结:我该怎么看这个模型?
当你画出你的程序在图中的点时:
- 如果点在斜线下: 别管算法逻辑了,去查查内存对齐、合并访问、减少全局内存读写。
- 如果点在平线下: 内存已经给力了,去查查循环展开、减少分支预测失败、利用 Tensor Core。
- 如果点在很低的位置(离屋顶很远): 说明你既没用好内存,也没用好计算,程序写得太“空转”了。
想不想试着分析一下你之前做的 TinyCUDA-BLAS
项目,大约落在 A100 屋顶线的哪个位置?
硬件的屋顶最大吞吐量为什么是固定的?对于任何算子都是这样吗?这是由什么决定的?计算强度是由算子决定而非硬件吗
这个问题直击 Roofline 模型的物理本质。我们分三个层次来彻底拆解它:
1. 硬件的“屋顶”高度为什么是固定的?
硬件的峰值吞吐量(水平线)和峰值带宽(斜线)确实是硬件设计指标,由物理结构决定:
- 水平线(Peak GFLOPS):由 [计算单元数量
× 时钟频率 × 每周期指令数] 决定。
- 比如 A100 有多少个 CUDA Core,每个 Core 每秒能跑多少次乘加运算(FMA)。一旦芯片造出来,频率定了,这个理论最大值就定死了。
- 斜线(Peak Bandwidth):由 [显存位宽 × 显存频率] 决定。
- 这相当于“高速公路”的总宽度。无论你运什么,路就那么宽。
2. 重点:对于任何“算子”都是固定的吗?
不是的。 这是一个非常关键的误区,实际上针对不同的指令类型,屋顶的高度是不一样的。
一张完整的 GPU Roofline 图其实有“多层屋顶”:
- 计算屋顶的分层:
- 最顶层:可能是使用 Tensor Core 跑半精度(FP16)矩阵运算的峰值。
- 中间层:可能是普通 FP32 单精度浮点运算的峰值。
- 底层:可能是 FP64 双精度或 Integer 整数运算的峰值。
- 结论: 不同的算子(如
exp开方对比add加法)对应的物理计算单元不同,屋顶高度也不同。
- 内存屋顶的分层:
- 最底层(全局显存):访问 HBM/DRAM 的带宽。
- 中间层(L2 Cache):访问二级缓存的带宽,通常比显存快好几倍。
- 最顶层(Shared Memory):访问片上共享内存的带宽,极高。
3. 计算强度(Arithmetic Intensity)是谁决定的?
计算强度主要由“算法(算子)逻辑”和“程序员的实现方式”共同决定。
由算子(算法)决定:
不同的数学逻辑,天生需要的计算强度不同。
- 向量加法 (C = A + B):读 2 个数,写 1 个数,中间只做 1 次加法。计算强度极低。
- 矩阵乘法 (C = A × B):数据重用率极高。对于 N × N 的矩阵,数据量是 O(N2),但计算量是 O(N3)。随着 N 增大,计算强度会线性增长。
由实现方式决定(重点):
同样的算子,如果你写得烂,计算强度就会变低。
- 实现 A(不带缓存):每次计算都去全局显存读数。分子(计算量)不变,分母(访存量)变大 → 计算强度低。
- 实现 B(带 Shared Memory 优化):读一次数,在片上寄存器里反复用 100 次。分母(访存量)大幅减少 → 计算强度显著提高。
4. 总结:三者的关系
我们可以用这个公式来总结你的疑问:
实际性能 = min (硬件峰值计算能力,计算强度×硬件峰值带宽)
- 硬件决定了: 两个“峰值”(公式里的常数项)。
- 你(程序员)和算子决定了: 计算强度(公式里的变量项)。
- Roofline 告诉了你: 在这个算子的逻辑下,你现在的实现方式是在“浪费钱”还是“榨干硬件”。
举个具体的思考题:
假设你正在写的 TinyCUDA-BLAS 在 A100 上跑,如果你把数据类型从 float 改成 half (FP16),此时 Roofline 的水平屋顶会变高(因为 A100 的 Tensor Core 处理 FP16 极快),而你的计算强度也会变化(因为每个数据占的字节减半了)。
既然你已经理解了计算强度,你想看看如何通过分析 Nsight Compute 的报告,来定位你的程序到底是卡在哪个“屋顶”下面吗?
根据屋顶线优化的目标是让它更接近拐点(无论是对于它的左侧还是右侧的点)还是说是要让他更接近最大吞吐率跟拐点没太大关系
这是一个非常核心的性能调优问题。简单直接的结论是:优化的终极目标永远是让点“向上”移动(更接近最大吞吐率),而“向拐点靠近”只是实现这一目标的手段或路径。
我们可以把 Roofline 模型看作一个“天花板”。你的程序就像一个在屋檐下的人,你总想跳得更高,但你会撞到不同形状的屋顶。
1. 为什么“最大吞吐率”才是真目标?
在高性能计算(HPC)中,我们最关心的指标是 GFLOPS(每秒算多少次)。
- 如果你的程序在拐点的左侧(内存受限),你通过优化让它向拐点移动(增加计算强度),你会发现它的 Y 轴坐标(吞吐率)也随之上升了。
- 如果你的程序已经在拐点右侧(计算受限),它已经贴着平的屋顶了,此时再往右移动,它的 Y 轴坐标(吞吐率)并不会增加。
2. 针对不同位置点的“调优策略”
根据你的程序点在图中的位置,优化的方向完全不同:
情况 A:点在拐点左侧(Memory-Bound)
- 状态:你的 GPU 核心在“等米下锅”,内存带宽被占满了。
- 目标:向右移动(靠近或跨越拐点)。
- 做法:通过增加计算强度来提高吞吐率。
- 减少访存量:使用 Shared Memory 缓存数据,减少对全局显存(DRAM)的访问。
- 增加重用:原本读一次数算 1 次,现在读一次数在寄存器里算 10 次。
- 结果:随着点向右移动,它会沿着“斜着的屋顶”往上爬,吞吐率(Y 轴)显著提升。
情况 B:点在拐点右侧(Compute-Bound)
- 状态:数据已经喂得足够快了,但计算单元(ALU/Tensor Core)已经满载,忙不过来了。
- 目标:向上移动(把屋顶抬高)。
- 做法:既然计算强度已经足够,向右移(做更多无效计算)没意义。你需要的是换更强的计算引擎:
- 使用 Tensor Core 替代普通的 CUDA Core。
- 将 FP32 指令换成更快的 FP16/INT8 指令。
- 结果:这本质上是换了一层更高的“水平屋顶”。你的点会垂直向上跳,达到更高的吞吐率。
情况 C:点在屋顶下方很远(效率低下)
- 状态:既没有占满带宽,也没有占满计算单元。
- 目标:垂直向上移动。
- 做法:解决代码中的“低效”问题:
- 解决分支发散(Warp Divergence):别让一半线程在看戲。
- 解决访存非对齐(Coalescing):别让一次内存请求只拿回一点点有效数据。
- 提高占用率(Occupancy):让更多 Warp 驻留在 SM 里掩盖延迟。
3. 拐点(Ridge Point)的真正意义
你之所以会觉得“靠近拐点”重要,是因为拐点代表了“最完美的平衡”。
- 在拐点处,你恰好榨干了所有的内存带宽,同时也恰好榨干了所有的计算能力。
- 对于硬件设计者:拐点越靠左,说明硬件越平衡;拐点越靠右(比如现在的 AI 芯片),说明计算力远超带宽,这种硬件对程序员的要求极高——你必须写出计算强度极大的代码(比如大矩阵乘法),才能不浪费硬件。
4. 总结
- 优化目标:让点在 Y 轴上越高越好。
- 路径:
- 如果你在左边,向右移动是通往高吞吐率的必经之路。
- 如果你在右边,向上切换屋顶(换算子、调精度)才是关键。
- 跟拐点的关系:拐点只是告诉你,你什么时候该改变优化策略了(从优化内存转为优化计算)。
既然你已经搞清楚了优化的方向,你现在的 RISC-V CPU 设计项目或者 TinyCUDA-BLAS 里面,有没有哪一部分是你觉得“怎么改吞吐率都不动”的?那可能就是你撞到了某个特定的屋顶了。
5.2 CUDA内存类型
在图的底部,我们看到全局内存和常量内存。这两种类型的内存都可以由主机进行写入(W)和读取(R)。全局内存也可以由设备进行写入和读取,而常量内存则支持设备进行短延迟、高带宽的只读访问。我们在第2章异构数据并行计算中介绍了全局内存,而在第7章卷积中将详细讨论常量内存

图 5.2 CUDA设备内存模型的(不完整)概述。图中未显示的一个重要类型的CUDA内存是纹理内存,因为本教材未涵盖其使用。
另一种类型的内存是本地内存(local memory),它也可以被读取和写入。本地内存实际上位于全局内存中,并具有类似的访问延迟,但它不跨线程共享。每个线程都有自己的一部分全局内存,它将其用作自己的私有本地内存,其中放置了线程私有但无法在寄存器中分配的数据。这些数据包括静态分配的数组、溢出的寄存器和线程调用堆栈的其他元素。
图5.2中的寄存器和共享内存是芯片上的内存。驻留在这些类型的内存中的变量可以以非常高的速度以高度并行的方式访问。寄存器分配给各个线程;每个线程只能访问自己的寄存器。典型的内核函数通常使用寄存器来保存对每个线程私有的频繁访问的变量。共享内存分配给线程块;块中的所有线程都可以访问为该块声明的共享内存变量。共享内存是线程通过共享其输入数据和中间结果来合作的有效手段。通过在CUDA内存类型中声明CUDA变量,CUDA程序员决定了变量的可见性和访问速度。
CPU与GPU寄存器架构
CPU和GPU之间不同的设计目标导致了不同的寄存器架构。正如我们在第4章计算架构和调度中看到的那样,当CPU在不同线程之间进行上下文切换时,它将外出线程的寄存器保存到内存中,并从内存中恢复传入线程的寄存器。相比之下,GPU通过将所有计划在处理块上的线程的寄存器保留在处理块的寄存器文件中来实现零开销调度。这样,线程warp之间的切换是即时的,因为传入线程的寄存器已经在寄存器文件中。因此,GPU寄存器文件的大小需要比CPU寄存器文件大得多
我们还在第4章计算架构和调度中看到,GPU支持动态资源分区,其中SM可以为每个线程提供少量的寄存器并执行大量的线程,或者为每个线程提供更多的寄存器并执行较少的线程。因此,GPU寄存器文件需要设计以支持寄存器的动态分区。相比之下,CPU寄存器架构为每个线程的寄存器分配了固定的寄存器集,而不考虑线程对寄存器的实际需求。

我们将非数组的变量称为标量变量。如表 5.1 所示,所有在内核和设备函数中声明的自动标量变量都被放置到寄存器中。这些自动变量的作用域限定在单个线程内。当内核函数声明一个自动变量时,对于执行内核函数的每个线程,都会生成该变量的私有副本。当线程终止时,所有其自动变量都将不复存在。
请注意,访问这些变量非常快速和并行化,但必须小心不要超出硬件实现中寄存器存储的有限容量。使用大量寄存器可能会对每个 SM 的占用产生负面影响
自动数组变量不存储在寄存器中(这个规则也有一些例外情况。如果所有访问都是使用常量索引值完成的,编译器可能会决定将自动数组存储到寄存器中。)。相反,它们存储在线程的本地内存中,并可能产生长时间的访问延迟和潜在的访问拥塞。这些数组的作用域,就像自动标量变量一样,限定在单个线程内。也就是说,为每个线程创建并由每个线程使用自动数组的私有版本。一旦线程终止其执行,其自动数组变量的内容就会消失。根据我们的经验,很少需要在内核函数和设备函数中使用自动数组变量。
如果变量声明前带有 __shared__ 关键字(每个“__”由两个“_”字符组成),则它在 CUDA 中声明了一个共享变量。也可以在声明前面添加可选的 device 来达到相同的效果。这样的声明通常在内核函数或设备函数中进行。共享变量驻留在共享内存中。共享变量的作用域在一个线程块内;也就是说,一个块内的所有线程看到同一个共享变量的版本。在内核执行期间,为每个块创建并使用共享变量的私有版本。共享变量的生命周期在内核执行期间。当内核终止其网格的执行时,共享变量的内容也将不复存在。正如我们之前讨论过的,共享变量是块内线程之间协作的有效手段。从共享内存中访问共享变量非常快速和高度并行化。CUDA 程序员通常使用共享变量来保存在内核执行阶段中经常使用和重复使用的全局内存数据的部分
如果变量声明前带有关键字 constant(每个“”由两个“_”字符组成),则它在 CUDA 中声明了一个常量变量。也可以在声明前面添加可选的 device 来达到相同的效果。常量变量的声明必须在任何函数体外。常量变量的作用域是所有网格,这意味着所有网格中的所有线程看到同一个常量变量的版本。常量变量的生命周期是整个应用程序的执行期间。常量变量通常用于向内核函数提供输入值的变量。常量变量的值不能被内核函数代码更改。常量变量存储在全局内存中,但会进行缓存以实现高效访问。通过适当的访问模式,访问常量内存是非常快速和并行化的。目前,应用程序中常量变量的总大小限制为 65,536 字节。可能需要分割输入数据量以适应此限制。我们将在第 7 章,卷积中演示常量内存的使用。
如果变量声明仅由关键字 device(每个“__”由两个“_”字符组成)前置,那么它是一个全局变量,并将放置在全局内存中。访问全局变量的速度较慢。最近的设备中使用缓存提高了访问全局变量的延迟和吞吐量。全局变量的一个重要优势是它们对所有内核的所有线程可见。它们的内容也在整个执行期间持续存在。因此,全局变量可以用作跨块(block)协作的手段。然而,必须注意,目前没有简单的方法可以在不使用原子操作或终止当前内核执行的情况下,在来自不同线程块的线程之间同步,或确保全局内存中的数据一致性。因此,全局变量通常用于将信息从一个内核调用传递到另一个内核调用。
在 CUDA 中,指针可以用于指向全局内存中的数据对象。指针在内核和设备函数中使用有两种典型方式。首先,如果一个对象是由主机函数分配的,那么该对象的指针将由内存分配 API 函数(如 cudaMalloc)初始化,并且可以作为参数传递给内核函数,正如我们在第 2 章,异构数据并行计算,和第 3 章,多维网格和数据中看到的那样。第二种使用方式是将在全局内存中声明的变量的地址分配给指针变量。例如,在内核函数中的语句 {float* ptr=&GlobalVar;} 将 GlobalVar 的地址分配给自动指针变量 ptr。读者应参考 CUDA 编程指南了解在其他内存类型中使用指针的方法。
5.3 减少内存访问的瓦片化(Tiling)
在CUDA中使用设备内存存在一个固有的权衡:全局内存容量大但速度慢,而共享内存容量小但速度快。一个常见的策略是将数据分割成称为瓦片的子集,以便每个瓦片都可以适应共享内存。瓦片一词来源于这样一个类比:一个大墙(即全局内存数据)可以由小瓦片(即每个都可以适应共享内存的子集)覆盖。一个重要的标准是,这些瓦片上的核心计算可以相互独立进行。请注意,并非所有数据结构都可以在任意的核函数中分割成瓦片。

图5.5 矩阵乘法的一个小例子。为了简洁起见,我们将M[y*Width+x]、N[y*Width+x]、P[y*Width+x]分别表示为My,x、Ny,x、Py,x
瓦片的概念可以通过第3章《多维网格和数据》中的矩阵乘法示例进行说明。图3.13展示了一个小型矩阵乘法示例。它对应于图3.11中的核函数。我们在图5.5中复制了该示例以便参考。为了简洁起见,我们将M[y*Width+x]、N[y*Width+x]、P[y*Width+x]分别表示为My,x、Ny,x、Py,x。该示例假设我们使用四个2 x 2块来计算P矩阵。P矩阵中的粗框定义了每个块处理的P元素。图5.5突出显示了block0,0的四个线程所做的计算。这四个线程计算P0,0、P0,1、P1,0和P1,1。线程0,0和线程0,1在block0,0中的M和N元素访问用黑色箭头标出。例如,线程0,0先读取M0,0和N0,0,然后是M0,1和N1,0,接着是M0,2和N2,0,最后是M0,3和N3,0。图5.6展示了block0,0中所有线程所做的全局内存访问。线程按垂直方向列出,水平方向的访问时间从左到右增加。请注意,每个线程在执行期间都会访问四个M元素和四个N元素。在突出显示的四个线程中,它们访问的M和N元素有很大的重叠。例如,线程0,0和线程0,1都访问了M0,0以及M的第0行的其余部分。类似地,线程0,1和线程1,1都访问了N0,1以及N的第1列的其余部分。

图3.11中的核函数编写得让线程0,0和线程0,1从全局内存中访问第0行的M元素。如果我们能够让线程0,0和线程0,1协作,使这些M元素仅从全局内存加载一次,我们就可以将对全局内存的总访问次数减半。实际上,我们可以看到在block0,0的执行过程中,每个M和N元素都被访问了两次。因此,如果我们可以让所有四个线程在访问全局内存时进行协作,我们就可以将对全局内存的流量减半。

在两个M和N瓦片加载到共享内存后,这些元素被用于点乘的计算。请注意,共享内存中的每个值都被使用了两次。例如,由线程1,1加载到Mds1,1中的M1,1值被线程1,0和线程1,1分别使用了一次。通过将每个全局内存值加载到共享内存中,使其可以被多次使用,我们减少了对全局内存的访问次数。在这种情况下,我们将全局内存的访问次数减少了一半。读者应该验证,如果瓦片是N x N元素,则减少的访问次数将是N的倍数。
还要注意,每个点乘的计算现在分成了两个阶段,在图5.8中分别表示为第1阶段和第2阶段。在每个阶段中,每个线程将输入矩阵元素的两对积累到Pvalue变量中。请注意,Pvalue是一个自动变量,因此为每个线程生成了一个私有版本。我们添加了下标只是为了说明这是为每个线程创建的不同实例的Pvalue变量。第1阶段的计算显示在图5.8的第四列中,第2阶段显示在第七列中。通常,如果输入矩阵的维度是Width,瓦片大小是TILE_WIDTH,则点乘将在Width/TILE_WIDTH个阶段中执行。创建这些阶段对于减少对全局内存的访问至关重要。由于每个阶段都专注于输入矩阵值的一个小子集,线程可以协作加载子集到共享内存,并使用共享内存中的值来满足在该阶段中的重叠输入需求。
还要注意,Mds和Nds在各个阶段之间被重用。在每个阶段中,相同的Mds和Nds被重用来保存用于该阶段的M和N元素的子集。这样一来,一个更小的共享内存就可以为大多数全局内存访问提供服务。这是因为每个阶段都专注于输入矩阵元素的一个小子集。这种专注的访问行为称为局部性。当算法表现出局部性时,就有机会使用小型高速存储器来服务大多数访问,并将这些访问从全局内存中删除。在多核CPU和多线程GPU中,实现高性能的关键在于局部性。我们将在第6章《性能考虑》中重新讨论局部性的概念。
这一章的核心其实是在讲一个非常简单的生活道理:与其每个人都跑一趟超市买同一瓶水,不如大家商量好,轮流去一次买一箱回来分。 📦
在 CUDA 编程中,全局内存(Global Memory)就像是那个很远很慢的超市,而共享内存(Shared Memory)就像是宿舍里的公用小冰箱。
让我们用三个步骤来拆解这个“瓦片化(Tiling)”技术:
1. 发现“浪费”:为什么我们要优化? 浪费在哪里?
在普通的矩阵乘法中,为了计算结果矩阵 P 的一个元素,线程需要读取 M 矩阵的一行和 N 矩阵的一列。
- 问题是: 线程 (0,0) 和 线程 (0,1) 都要用 M 矩阵的第 0 行。
- 结果: 它们各自都会跑去全局内存读取一遍。如果一个 Block 有 16x16 个线程,同样的 M 行数据就被重复读取了 16 次!这在速度极慢的全局内存面前是巨大的带宽浪费。 🐢
2. 瓦片策略:化整为零 🧱
“瓦片”就是把巨大的矩阵切成一小块一小块。
- 协作加载: 一个 Block 里的所有线程不再各顾各,而是协作。比如要计算 2x2 的区域,四个线程一起动手,每人只从全局内存搬 一个 元素到共享内存里。
- 共享成果: 搬完后,大家直接从小冰箱(共享内存)里拿数据计算。这样,原本需要从超市搬 4 次的数据,现在只需要搬 1 次。
3. 分阶段执行:接力賽 🏃♂️
因为共享内存很小,放不下整个矩阵,所以我们要分阶段(Phases):
- 阶段 1: 大家一起搬第一组瓦片到共享内存 → 同步等待(确保大家都搬完了) → 在共享内存里做局部乘加。
- 阶段 2: 清空刚才的共享内存,大家再一起搬第二组瓦片 → 同步等待 → 继续做局部乘加。
- 循环: 直到整行整列都算完。
让我们通过一个细节来测试一下理解:
文中的图 5.8
提到,在每个阶段开始时,线程都要协作搬运。假设我们现在有一个 16 × 16 的线程块(即
TILE_WIDTH = 16)。
问题: 如果我们使用这种瓦片化技术,相比于最原始的方案(每个线程直接去全局内存读),我们理论上能把访问全局内存的次数减少到原来的多少分之一?(提示:看看文中提到的减少量和块的维度有什么关系)
我将一路引导你理解这些概念。 🤝
通过将每个全局内存值加载到共享内存中,使其可以被多次使用,我们减少了对全局内存的访问次数。在这种情况下,我们将全局内存的访问次数减少了一半。读者应该验证,如果瓦片是N x N元素,则减少的访问次数将是N的倍数。
这是一个非常敏锐的观察!你之所以觉得是“1/2”,是因为刚才那个 2x2 的例子里,每个数据刚好被使用了 2 次。
但我们要看的是“数据重用率”如何随瓦片(Tile)的大小而变化。我们可以一起推导一下这个规律。
1. 为什么 2x2 瓦片减少了 1/2?
在 2x2 的例子中:
- 计算任务:一个 Block 负责计算 P 矩阵中 2x2 的区域(共 4 个元素)。
- 数据需求:为了算这 4 个元素,每个线程都要用到 M 的某一行和 N 的某一列。
- 重用情况:
- M0, 0 被线程 (0,0) 和线程 (0,1) 使用了(共 2 次)。
- N0, 0 被线程 (0,0) 和线程 (1,0) 使用了(共 2 次)。
- 结论:原本要从全局内存读 2 次的东西,现在进共享内存只读 1 次,所以访问量变成了原来的 1/2。
2. 如果瓦片变成 N × N 呢?
想象一下,如果我们的瓦片大小(TILE_WIDTH)是 16:
- 这个 Block 现在负责计算 P 矩阵中 16 × 16 的区域。
- 对于 M
矩阵中的某一个元素(比如瓦片左上角的 M0, 0):
- 在计算 P0, 0, P0, 1, P0, 2…P0, 15 这 16 个结果时,是不是都会用到 M0, 0?
- 这意味着,如果不使用共享内存,这一个 M0, 0 会被重复读取 16 次。
- 使用了共享内存后,这个 Block 的 256 个线程协作,只读 1 次 M0, 0 到共享内存里,然后供这 16 个线程反复使用。
3. 核心逻辑总结
我们可以用下表对比一下全局内存的访问压力:
| 方案 | 每个元素被读取的次数 | 总访问量(相对于数据量) |
|---|---|---|
| 无瓦片化 | 每个 M 元素被读 TILE_WIDTH 次 | TILE_WIDTH × 数据量 |
| 瓦片化 | 每个 M 元素只从全局内存读 1 次 | 1 × 数据量 |
所以,全局内存的访问量从 N 次降到了 1 次,也就是减少到了原来的 1/N。
让我们做个小思考:
如果矩阵非常大(比如 1024 × 1024),而我们的 TILE_WIDTH 设置为 32。
- 在计算过程中,每一个从全局内存加载到共享内存的 M 元素,会被同一个 Block 里的多少个线程重复使用?
- 这对应了屋顶线(Roofline)模型中的哪个改变(是让点向右移动了,还是向上移动了)?
tile的目的不是为了把原本的大数据切割成小块吗?那按理说应该越小越好,这里怎么反而N越大越节省了
这是一个非常敏锐的直觉!你可能在想:如果瓦片(Tile)分得越小,管理起来不是越灵活、占用的资源越少吗?
但这里我们要区分两个完全不同的概念:管理成本(比如共享内存够不够大)和数据重用率(也就是你能省下多少次去“超市”买东西的次数)。
我们一起来分析一下为什么 N 越大反而越省:
1. “邻居”之间的羊毛 🐑
在矩阵乘法中,并不是每个线程都在读完全不同的数据。
- 行的重用: 在一个 Thread Block 里,同一行的线程都在读 M 矩阵的同一行。
- 列的重用: 同一列的线程都在读 N 矩阵的同一列。
2. N 的大小决定了“羊毛”能薅多少次
假设我们要计算结果矩阵 P。
- 如果 N = 2(2x2 的瓦片):
- 每个 M 元素被读进共享内存后,只有 2个 线程会用到它。
- 你把原本 2 次的全局内存访问变成了 1 次。
- 如果 N = 16(16x16
的瓦片):
- 每个 M 元素被读进共享内存后,这一个 Block 里的 16个 线程都会用到它!
- 你把原本 16 次的全局内存访问变成了 1 次。
发现规律了吗? N 越大,意味着一个瓦片内部的“邻居”越多,大家平摊下来的“运费”(全局内存访问次数)就越低。
3. 既然如此,为什么不无限大? 🛑
虽然理论上 N 越大越省流量,但现实中我们被两个硬性条件拽住了:
- 共享内存容量(Shared Memory): 每个 SM 的共享内存是有限的(通常几十 KB)。如果 N 太大,瓦片根本塞不进“冰箱”。
- 线程限制: 一个 Block 的最大线程数通常是 1024。
练手思考题 🧠
回到我们之前的例子,如果 M 和 N 矩阵的维度是 1024 × 1024。
如果我们不用 Tiling(瓦片化),计算整个 P 矩阵,对 M 矩阵的总访问次数是 10243。
如果我们使用 32 × 32 的瓦片(即 N = 32),那么对 M 矩阵的总访问次数会变成多少?(你可以试着从“每个元素被读了多少次”这个角度来想)
5.4 使用分块矩阵乘法内核
现在我们准备介绍一个使用共享内存来减少对全局内存访问量的分块矩阵乘法内核。
图5.9中显示的内核实现了图5.8中所示的阶段。在图5.9中,第4行和第5行分别声明了Mds和Nds为共享内存数组。回想一下,共享内存变量的作用域是一个块。因此,Mds和Nds数组的每个块都将创建一个版本,块的所有线程都可以访问相同的Mds和Nds版本。这一点很重要,因为块中的所有线程必须能够访问由其同行加载到Mds和Nds中的M和N元素,以便它们可以使用这些值来满足其输入需求。【本kernel函数只能处理WIDTH x WIDTH的两个方阵的乘法。】

图5.9 使用共享内存的分块矩阵乘法内核。
要把图 5.9 的代码看懂,关键在于区分哪些是“线程私有的坐标”,哪些是“矩阵全局的坐标”。我们配合代码行号来拆解。
1. 确定身份:我是谁?(第 11-12 行)
每个线程启动时,首先要确定自己负责结果矩阵 P 的哪个位置。
Col = bx * TILE_WIDTH + tx;Row = by * TILE_WIDTH + ty;
这里 bx, by 是块的编号,tx, ty
是块内线程的编号。这就像在班级里:“几组(bx)+ 组内第几个(tx)=
班级总序号”。这组坐标在整个计算过程中是不变的,决定了该线程最终把结果写到
P 的哪个坑位(第 29 行)。
2. 协作搬运:我们要搬哪块砖?(第 19-20 行)
这是最难理解的地方。for 循环中的 ph 代表“阶段(Phase)”。
为了算出一整行乘以一整列,我们把这长长的一条切成了若干个 Tile(瓦片)。
M
矩阵的访问:M[Row * Width + (ph * TILE_WIDTH + tx)]
- 行坐标 (
Row):因为我负责 P 的某一行,所以我永远只读 M 的这一行。 - 列坐标
(
ph \* TILE_WIDTH + tx):随着阶段ph的增加,我们一小段一小段地向右移动。注意,这里用的是tx!这意味着块内的每一列线程负责搬运瓦片里对应列的那个元素。
N
矩阵的访问:N[(ph * TILE_WIDTH + ty) * Width + Col]
- 行坐标
(
ph \* TILE_WIDTH + ty):随着阶段增加,我们一小段一小段地向下移动。这里用的是ty! - 列坐标 (
Col):因为我负责 P 的某一列,所以我永远只读 N 的这一列。
结果: 整个 Block 的线程协作,把 M 的一块和 N 的一块分别“平移”到了共享内存
Mds 和 Nds 中。
3. 同步屏障:等大家搬完(第 21 行)
__syncthreads();
这是一个“集结令”。因为线程跑得快慢不一,我们必须确保所有线程都完成了搬运任务,共享内存里的瓦片才是完整的。否则,如果我还没搬完你就开始算,数据就错了。
4. 局部计算:在小冰箱里干活(第 23-25 行)
Pvalue += Mds[ty][k] * Nds[k][tx];
注意看,这里的索引不再有 Row 或 Col 了,全是 ty, tx 和循环变量 k。
因为数据已经进到了“小冰箱”(共享内存)里,我们只需要在
TILE_WIDTH这么大的范围内做点积。这个循环做完,我们只是完成了整行乘整列的 一部分(即一个阶段)。
5. 循环往复与最终写入(第 26-29 行)
- 第 26 行的同步:计算完这一阶段后,又要
__syncthreads()。这是为了确保大家都用完了当前的瓦片,这样我们才能安全地清空“冰箱”,去搬下一个阶段(下一个ph)的瓦片。 - 第 29 行:当所有的
ph阶段都跑完,Pvalue里就攒好了最终的数值。这时候,线程才把这个值一次性写回最慢的全局内存 P 中。
总结:索引的精髓
- 全局索引 (
Row,Col):用于去大仓库(全局内存)里定位。 - 局部索引 (
tx,ty):用于在小冰箱(共享内存)里协作。 - 阶段索引
(
ph):用于控制我们在长长的行/列里走到了哪一站。
Col = bx * TILE_WIDTH + tx; Row = by * TILE_WIDTH + ty; 这里为什么是*TILEWIDTH,不应该是BLOCK-size吗
这是一个非常细致的观察!其实在 CUDA
编程的习惯中,TILE_WIDTH 和 Block Size
在数值上通常是完全相等的,但它们在语义上代表了不同的含义。
在你提供的这段代码中,这种写法是为了保持硬件逻辑与算法逻辑的高度一致。
1. 语义上的区别:为什么叫不同的名字?
虽然它们的值可能都是 16,但它们描述的对象不同:
Block Size(硬件维度):这是从 GPU 线程组织的角度看的。它定义了一个线程块(Block)里有多少个线程。TILE_WIDTH(算法/数据维度):这是从矩阵分块的角度看的。它定义了一个“瓦片”(Tile)在矩阵里覆盖了多少行、多少列的数据元素。
在这份代码的实现里,作者设定了“一个线程负责计算一个结果元素”,且“一个线程块正好负责一个瓦片”。因此,Block Size
必须等于 TILE_WIDTH。
2. 为什么用
* TILE_WIDTH?
计算 Row 和 Col
的公式是为了定位当前线程在整个大矩阵中的全局位置:
bx \* TILE_WIDTH:bx是当前块在水平方向上的序号。每个块负责处理宽度为TILE_WIDTH的一小段区域。所以bx * TILE_WIDTH是计算出当前块左边界在全局矩阵中的偏移量。+ tx:这是当前线程在块内部的局部偏移。
如果这里写成
\* BlockSize,逻辑上也是通的,但不够直观。 因为
Row 和 Col
最终是用来访问矩阵数组索引的,使用代表“数据分块宽度”的
TILE_WIDTH
能让代码更具可读性,一眼看出这是按照瓦片的大小在进行全局寻址。
3. 一个极端的例子(如果不相等会怎样?)
为了让你彻底明白为什么这里强调
TILE_WIDTH,我们可以假设一种“非对称”的情况:
假设每个线程负责计算 2 个 结果元素:
- 此时你的
Block Size依然是 16。 - 但你的
TILE_WIDTH就会变成 32(因为一个 Block 要处理 32 列数据)。 - 在这种情况下,公式就必须使用
TILE_WIDTH(或者相关的逻辑变量),如果误用了Block Size(16),算出来的全局索引就会发生重叠,导致计算错误。
总结
在图 5.9 的代码里,TILE_WIDTH
既是共享内存数组的维度,也是线程块的维度。这种“一一对应”的设计简化了计算:
- 第 1 行:定义了
TILE_WIDTH为 16。 - 配置核函数时:程序员会手动设置
blockDim.x = TILE_WIDTH。 - 代码内部:统一使用
TILE_WIDTH来保证搬运到共享内存的数据量(瓦片大小)与执行计算的线程数量完美匹配。
理解了这里的索引映射后,你发现第 19 行加载 M 矩阵和第 20 行加载 N 矩阵时,索引里的 + tx
和 + ty
为什么是反着的吗?这其实涉及到了行优先存储的访问逻辑。
我还是不明白,正常设计中tile的大小都是等于block的吗?如果这两不相等的时候(假如blocksize为16,tile为32),那么到了第二个block,原本的索引blockIdxblockDim+thread.x(116+1)和他的计算结果(乘tile-size来进行全局内存访问)(1*32+1)这两完全不一样,前者才是正确的吧。
这是一个非常棒的逻辑思考!你已经触及了 CUDA 编程中从“基础教材”向“工程实践”跨越时最核心的矛盾:硬件线程组织(Block Size)与算法逻辑分块(Tile Size)的解耦。
回答你的核心疑问:它们不一定相等。 虽然在很多入门示例(包括你阅读的这段教材)中它们是相等的,但在高性能内核中,它们经常被设为不同的值。
为了化解你关于“116”和“132”的迷茫,我们需要引入一个被你暂时忽略的“第三方变量”:Grid 的尺寸(Grid Dimension)。
1. 关键:谁决定了
blockIdx 的含义?
你之所以觉得“1*16+1”才是正确的,是因为你潜意识里认为:“每一个 Block 必须紧挨着前一个 Block 处理数据”。
但实际上,blockIdx 代表什么,完全取决于你在 CPU
端启动核函数时的配置:
- 配置 A(1:1 模式): 如果你设置
gridDim.x = Width / 16。那么blockIdx.x = 1确实代表第 16 个像素开始。此时公式必须是blockIdx * 16 + tx。 - 配置 B(瓦片模式): 如果你设置
gridDim.x = Width / 32。那么blockIdx.x = 1就不再代表第 16 个像素,而是代表第 32 个像素开始。此时公式就必须是blockIdx * 32 + tx。
结论: 索引公式中的 * TILE_WIDTH
必须与你在 CPU 端计算 Grid 大小时使用的分母保持高度一致。如果 CPU 端按
32 分块,核函数内部就得按 32 偏移。
2. 为什么会让 BlockSize < TILE_WIDTH?(进阶技巧:Thread Tiling)
在你提到的 BlockSize = 16 但
TILE_WIDTH = 32 的情况下,一个 Block 只有 16 × 16 = 256 个线程,但它面对的瓦片却有
32 × 32 = 1024 个元素。
这该怎么办?答案就是:让一个线程多干点活(Work Coarsening)。
在这种设计下:
- 搬运阶段:每个线程不再只搬 1 个元素到共享内存,而是通过一个循环搬运 4 个 元素。
- 计算阶段:每个线程负责计算 P 矩阵中 2 × 2 的区域,而不是 1 个点。
这样做的好处:
- 增加寄存器重用:一个线程把 M 的值读进寄存器,可以立马跟 N 的多个值相乘,减少了对共享内存的访问次数。
- 掩盖延迟:单线程指令变多,有助于更好地隐藏内存存取延迟。
3. 修正你的索引逻辑
让我们用你的例子(BlockSize = 16, TILE_WIDTH = 32)重新梳理第
2 个 Block(blockIdx.x = 1)的定位:
- CPU 端代码:
dim3 grid(Width/32, Height/32); - GPU 端代码(定位第 1 个线程):
Col = bx * TILE_WIDTH + tx;→ 1 * 32 + 0 = 32。- 重点来了: 这个 Block 里的线程
tx=0现在的起始位置是 32。因为前一个 Block(bx=0)已经处理完了 0 到 31 号元素。
为什么不会漏掉数据?
因为你把 Grid 设小了(除以了 32),所以 blockIdx.x=1 实际上是原本 1:1 模式下的“第 3 个 Block”的位置。中间的缺口,已经由每个线程内部处理多个元素的逻辑填补上了。
4. 总结与建议
在普通的 CUDA 教学中,为了降低理解难度,教材会默认 BlockSize = TILE_WIDTH = 16。这种情况下:
- 线程 16 × 16 刚好覆盖 16 × 16 的数据区。
- 每个线程搬 1 个数,算 1 个数。
但你在做 TinyCUDA-BLAS
这种项目时,一定要打破这个等号。 高性能的
GEMM(通用矩阵乘法)内核中,通常是 BlockSize = 256(线程),但处理的是
128 × 128 的巨大瓦片(TILE_WIDTH = 128),这意味着每个线程要处理多个
8 × 8 的微型瓦片。
思考与练习
回到你正在看的代码(图 5.9),如果我们将 TILE_WIDTH 改为 32,但保持线程块大小为 dim3 block(16, 16),第 19 行加载 M 矩阵的代码:
Mds[ty][tx] = M[RowWidth + phTILE_WIDTH + tx];
如果不加修改,这段代码只会搬运瓦片的左上角 16 × 16 区域。
你愿意尝试一下,如何修改第 19 行,让这 256 个线程能够协力搬完 32 × 32 的数据吗?
第21行中的屏障__syncthreads()确保所有线程在任何一个线程继续之前都已经完成了M和N的瓦片加载到Mds和Nds中。__syncthreads()确保所有线程在移动到下一个迭代并从下一个瓦片加载元素之前,所有线程都已经完成使用共享内存中的M和N元素。因此,没有一个线程会提前加载元素并破坏其他线程的输入值。
第21行和第26行中的两个__syncthreads()调用展示了并行程序员在协调线程之间时经常必须考虑的两种不同类型的数据依赖关系。第一种称为写后读(read-after-write)依赖,因为线程必须等待其他线程将数据写入到正确位置后才能尝试读取。第二种称为读后写(write-after-read)依赖,因为线程必须等待所有需要的数据被所有线程读取后才能进行写入。
写后读和读后写依赖的其他名称分别是真依赖和假依赖。写后读依赖是真依赖,因为读取线程确实需要写入线程提供的数据,因此它别无选择,只能等待。读后写依赖是假依赖,因为写入线程不需要读取线程的任何数据。这种依赖关系是由于它们重用相同的内存位置造成的,并且如果它们使用不同的位置,则不会存在
这是一个非常经典的问题,理解“读后写(Write-after-Read)”依赖是写好高性能并行程序的关键。
我们先看结论:第 26 行的同步是为了保护“还没被用完”的旧数据不被“新搬来”的数据给覆盖掉。
1. 为什么第 26 行需要同步?
在这个 Kernel 的 for 循环里,共享内存 Mds
和 Nds 是被重复利用的。
让我们分步骤看:
- 阶段 1 (ph=0):大家一起搬数据到共享内存 → 同步 (第21行) → 进行计算。
- 阶段 2 (ph=1):循环回到开头,大家又要搬新的数据到共享内存。
危险点就在这里:
由于每个线程的计算速度不同,可能线程 A 还在做第 24 行的累加计算(正在读取 阶段 1 的共享内存),而线程 B 已经跑得飞快,准备进入下一个循环去执行第 19 行的加载操作了(准备写入 阶段 2 的数据)。
如果线程 B 不等线程 A,它会直接把 阶段 2 的数据覆盖到共享内存里。此时线程 A 读到的就是错的数据(一半是旧的,一半是新的),计算结果瞬间崩盘。
所以第 26 行的 __syncthreads() 是在说:
“大家先别急着去搬下一波货,等所有人都把手里这波货(当前的
Tile)吃干抹净了,我们再统一清空冰箱搬下一波。”
2. 为什么叫“假依赖” (False Dependency)?
这个名字听起来很奇怪,但它揭示了问题的本质:这种依赖不是因为“数据”本身,而是因为“内存地址”不够用。
- 真依赖 (写后读 RAW):
- 逻辑:我必须等你的数据算出来,我才能接着算。
- 本质:数据之间有逻辑上的因果关系。就算你有无限的内存,我也得等你。
- 假依赖 (读后写 WAR):
- 逻辑:我必须等你看完这页书,我才能在上面涂改。
- 本质:这是由于内存空间重用造成的冲突。
- 验证:正如书中所说,如果你有无限的内存,每一轮
ph都使用一组全新的、不重叠的共享内存数组(比如Mds_ph0,Mds_ph1…),那么这个同步(第 26 行)就可以直接删掉。 因为线程 B 写它的新地址,完全不会影响线程 A 读它的旧地址。
3. 形象比喻:黑板报
- 写后读 (真):画画的人(写入线程)还没画完,看画的人(读取线程)必须等着,否则画是不完整的。
- 读后写
(假):看画的人还没看完,擦黑板准备画下一期的人(准备覆盖写入的线程)必须等着。
- 为什么假? 因为如果学校有无限长的黑板,擦黑板的人可以直接去旁边的新黑板画,根本不需要等你看完。只是因为黑板只有这一块,所以才产生了这种“虚假”的等待。
这种“双重同步”是分块算法(Tiling)的标准配置。既然提到了共享内存的重用,你有没有想过,如果共享内存足够大,大到能放下整个矩阵,我们的代码是不是就可以省掉所有
__syncthreads() 了?
从第16行到第28行的循环嵌套展示了一种称为分块(strip mining)的技术,该技术将长时间运行的循环分解成阶段。每个阶段涉及内部循环,该内部循环执行原始循环的一些连续迭代。原始循环成为外部循环,其作用是按顺序迭代地调用内部循环,以便执行原始循环的所有迭代。通过在内部循环之前和之后添加屏障同步,我们强制同一块中的所有线程在每个阶段都集中精力处理同一部分输入数据。分块是在数据并行程序中创建所需阶段的重要手段。
完成所有点积阶段后,执行退出外部循环。在第29行,所有线程使用从Row和Col计算得到的线性化索引写入其P元素。分块算法的好处是巨大的。对于矩阵乘法,全局内存访问量减少了TILE_WIDTH倍。使用16x16的瓦片,可以将全局内存访问量减少16倍。这将计算与全局内存访问的比率从0.25 OP/B提高到4 OP/B。这种改进使CUDA设备的内存带宽能够支持更高的计算速率。例如,在A100 GPU中,其全局内存带宽为1555 GB/秒,这种改进使设备可以达到(1555 GB/秒) * (4 OP/B) = 6220 GFLOPS,远高于未使用分块的内核实现的389 GFLOPS。
尽管分块大大提高了吞吐量,6220 GFLOPS仍然只是设备峰值吞吐量19500 GFLOPS的32%。可以进一步优化代码以减少全局内存访问次数并提高吞吐量。我们将在本书的后面看到其中一些优化,而其他高级优化将不会涵盖。由于矩阵乘法在许多领域中都非常重要,因此有高度优化的库,如cuBLAS和CUTLASS,已经包含了许多这些高级优化。程序员可以使用这些库立即在其线性代数应用程序中实现接近峰值性能。
分块矩阵乘法内核提高了矩阵乘法特别是应用程序的吞吐量,这并不是GPU独有的。长期以来,在CPU上应用分块(或阻塞)技术以提高性能有着悠久的历史,它确保了CPU线程在特定时间窗口内重复使用的数据将在缓存中找到。一个关键区别是,CPU上的分块技术依赖于CPU缓存隐式地将重复使用的数据保存在芯片上,而GPU上的分块技术使用共享内存显式地将数据保存在芯片上。原因是CPU核心通常一次运行一个或两个线程,因此一个线程可以依赖于缓存保持最近使用的数据。相比之下,GPU SM同时运行许多线程以隐藏延迟。这些线程可能会竞争缓存槽,这使得GPU缓存不太可靠,因此需要使用共享内存来保存要重复使用的重要数据。
虽然分块矩阵乘法内核的性能提高令人印象深刻,但它确实做出了一些简化假设。
- 首先,假定矩阵的宽度是线程块的宽度的倍数。这防止了内核正确处理具有任意宽度的矩阵。
- 第二个假设是矩阵是方阵。在实践中,这并不总是正确的。在下一节中,我们将介绍一个带有边界检查的内核,以消除这些假设。
这段话描述的分块技术就是这个代码要讲的tiling吗?还是说这是别的技术?和thread tiling又是一样的吗
这是一个非常敏锐的术语辨析!简单来说,你提到的这三个概念(Tiling, Strip Mining, Thread Tiling)在底层逻辑上是同源的,但在应用层次和侧重点上有所不同。
我们可以这样理解它们之间的关系:
1. Strip Mining(分块/带状开采):通用的循环转换技术
文中提到的 Strip Mining 是一种经典的编译器优化技术。
- 本质:它将一个超长的循环(比如从 0 到 1024)拆分成两个嵌套循环:外层循环按“段(Strip)”前进,内层循环在段内进行连续迭代。
- 在代码中的体现:第 16 行的
for(ph = 0; ...)就是外层循环,它把原本一整行 M 的点积拆成了多个阶段(Phases)。 - 目的:它本身不改变计算量,但它为数据局部性提供了物理基础。如果没有这个拆分,你就没法在每一小段之前安插同步指令。
2. Tiling(瓦片化):结合了内存层次的 Strip Mining
Tiling 是 Strip Mining 在多维数据(如矩阵)上的应用,并且专门针对内存层次结构(如共享内存)进行了优化。
- 区别:Strip Mining 只是把循环拆开,而 Tiling 明确要求将拆出来的这一小块数据(Tile)搬运到更快的存储器(Shared Memory)中。
- 协作性:在 CUDA 中,Tiling 强调线程间的协作。大家一起通过 Strip Mining 产生的“阶段”,把数据从全局内存搬到共享内存,实现重用。
- 总结:这段代码讲的 Tiling 技术,其手段是 Strip Mining,其目的是减少全局内存访问。
3. Thread Tiling:更高阶的优化
你提到的 Thread Tiling(有时也叫 Register Tiling)是更进一步的技术,它与图 5.9 的代码有显著不同:
- 图 5.9 的代码:一个线程只负责计算 P 矩阵中的 1 个 元素。
- Thread Tiling:一个线程负责计算 P 矩阵中的 一小块(比如 4 × 4) 元素。
- 核心差异:
- Tiling 是为了在 Thread Block 级别重用数据(通过 Shared Memory)。
- Thread Tiling 是为了在 Thread 级别重用数据(通过 寄存器 Register)。
三者对比表
| 技术名称 | 操作对象 | 存储介质 | 主要目的 |
|---|---|---|---|
| Strip Mining | 循环结构 | N/A | 将大循环分解为可控的阶段 |
| Tiling (本章代码) | 线程块 (Block) | 共享内存 (Shared Memory) | 减少全局内存访问量,提高带宽利用率 |
| Thread Tiling | 单个线程 (Thread) | 寄存器 (Register) | 减少共享内存访问量,进一步提升计算强度 |
总结
你阅读的这段话是想告诉你:我们利用了 Strip Mining 这种循环改写的方法,在代码中实现了 Tiling 这种算法策略。它们不是互相排斥的,而是“工具”与“方案”的关系。
而 Thread Tiling 是你接下来在优化
TinyCUDA-BLAS 时会用到的绝招——它能让你的点在 Roofline
模型上进一步向右、向上移动。
既然你已经理解了阶段(Phase)的概念,如果我要你修改这段代码,让每个线程一次性计算
P
矩阵中纵向相邻的两个元素(从而实现初步的 Thread Tiling),你觉得
Mds 和 Nds
的读取逻辑会发生什么变化?
循环展开(Loop Unrolling) 是一个非常关键的底层优化手段。
简单来说,循环展开就是通过减少循环次数、增加单次循环内的计算量,来降低循环开销并提升硬件并行效率的技术。
1. 它是如何操作的?
假设我们有一个简单的向量加法循环:
C++
1 | |
如果我们进行 2 倍展开(Unroll by 2),代码会变成这样:
C++
1 | |
2. 为什么要费力做这种转换?(核心好处)
你可能会觉得这只是把代码变长了,但在底层硬件层面,它有巨大的优势:
A. 减少“行政开销” (Reduced Overhead)
原本的循环每执行一次计算,都要进行一次 i < 100
的逻辑判断和一次 i++
的自增操作。展开后,这些“管理性”指令的比例大幅下降,处理器可以将更多精力放在真正的加法运算上。
B. 提升指令级并行(ILP)
这是最重要的一点。在 CPU 或 GPU 内部,指令是流水线化的。
- 展开前:后续的加法可能需要等待前一次加法索引更新完成,存在数据依赖。
- 展开后:
a[i]和a[i+1]的计算通常是互相独立的。硬件调度器可以同时发射(Issue)这两条指令,充分利用多功能计算单元(ALU)。
C. 辅助编译器优化
展开后的代码给了编译器更大的空间去进行“指令重排”。例如,它可以先把
b[i] 和 b[i+1]
一次性通过更宽的指令读进来(向量化访存),然后再统一计算。
4. 循环展开有没有代价?
并不是展开越多越好,它存在一个“边际效应递减”:
- 指令缓存(I-Cache)压力:代码变长会导致程序体积膨胀,如果展开得太过分,可能会挤爆 CPU/GPU 的指令缓存,反而变慢。
- 寄存器压力:更多的并行计算意味着需要更多的临时寄存器来存储中间变量。如果寄存器不够用了,就会发生 Register Spilling(数据溢出到缓慢的内存中),性能会垂直落体。
总结
循环展开是“用空间换时间”的典型做法。它打破了循环的界限,让硬件看清更多的计算机会,从而实现更高的吞吐量。
既然你在准备面试,想不想了解一下在 CUDA
编译器中,#pragma unroll 后面跟一个具体的数字(比如
#pragma unroll 4)会有什么特殊的控制效果?
5.5 边界检查
现在我们将扩展分块矩阵乘法内核以处理具有任意宽度的矩阵。这些扩展将允许内核正确处理宽度不是瓦片宽度的倍数的矩阵。让我们将图5.7中的小例子改为使用3x3的M、N和P矩阵。修订后的例子如图5.11所示。请注意,矩阵的宽度为3,不是瓦片宽度(为2)的倍数。图5.11显示了第0块0,0的第二阶段的内存访问模式。我们看到线程0,1和线程1,1将尝试加载不存在的M元素。同样,我们看到线程1,0和线程1,1将尝试访问不存在的N元素。

到目前为止,从我们的讨论来看,问题访问似乎只在线程执行的最后一个阶段中出现。这可能表明我们可以在分块内核执行的最后阶段采取特殊的操作来处理它。不幸的是,这并不正确。问题访问可能在所有阶段中出现。
请注意,这些问题访问无法通过简单地排除不计算有效P元素的线程来预防。例如,第1块1,1中的线程1,0不计算任何有效的P元素。然而,它需要在阶段0中加载M2,1,以供第1块1,1中的其他线程使用。此外,请注意,一些计算有效P元素的线程将尝试访问不存在的M或N元素。例如,正如我们在图5.11中看到的,块0,0中的线程0,1计算一个有效的P元素P0,1。然而,它在阶段1中尝试访问不存在的M0,3。这两个事实表明,我们需要使用不同的边界条件测试来加载M瓦片、加载N瓦片和计算/存储P元素。一个可以遵循的经验法则是,每个内存访问都需要相应的检查,以确保访问中使用的索引在所访问的数组的边界内。
如果条件为假,则线程不应加载该元素。问题是应该将什么放入共享内存位置。答案是0.0,这是一个不会在内积计算中造成任何伤害的值。如果任何线程在其内积计算中使用这个0.0值,那么内积值不会发生任何变化。
最后,只有在负责计算有效P元素时,线程才应存储其最终内积值。此条件的测试是(Row < Width)&& (Col < Width)。带有额外边界条件检查的内核代码如图5.13所示。

图5.13 带有边界条件检查的分块矩阵乘法核心。
这段话的核心是在提醒你:在 CUDA 的 Tiling(瓦片化)算法中,边界检查不能只做一次,必须分头行动。
通常我们写 CPU 代码,只要 if (i < Width)
成立就万事大吉了。但在分块(Tiling)内核里,情况变得复杂,因为搬运数据的线程和最后计算结果的线程,它们面临的“合法性”标准是不一样的。
1. 核心矛盾:计算无效,但搬运有用
你可能觉得:如果一个线程对应的 P 矩阵位置已经超出范围了,那这个线程直接“休息”不就好了吗?
书里告诉你:不行!
- 例子:假设矩阵是 3 × 3 的,而你的 Block 是 2 × 2。
- 计算层面:第四个线程(Idx 1,1)对应的位置是 (3,3),这超出了 3 × 3 矩阵的范围,它确实不需要计算 P 元素。
- 搬运层面:但是!在 Tiling 逻辑中,这个线程负责搬运 M 矩阵中对应的某个位置数据到共享内存。如果这个数据是其他“合法”线程(比如负责计算 P2, 2 的线程)需要的,那么这个“超出边界”的线程也必须参与搬运。
2. 为什么“每个阶段”都可能出问题?
你可能认为只有矩阵最右边、最下边的 Tile 才会越界。但书里指出:问题访问可能在所有阶段中出现。
- 当我们把 M
矩阵横向切成瓦片时,虽然你的
Row(行索引)是合法的,但随着ph(阶段)增加,瓦片的列索引可能会超出矩阵的宽度。 - 同理,N 矩阵的行索引也可能在某个阶段超出高度。
这意味着,即便这个线程负责的 P 元素是合法的,它在某个特定阶段搬运 M 或 N 的瓦片时,也可能踩到空地。
3. 三套独立的“准入证” (经验法则)
书里提到的“经验法则”要求你把边界检查拆成三部分,不能混为一谈:
- 加载 M 瓦片的准入证:检查当前要读的 M 矩阵位置
(Row, ph*TILE_WIDTH + tx)是否在 M 的范围内。如果不在,往Mds填 0。 - 加载 N 瓦片的准入证:检查当前要读的 N 矩阵位置
(ph*TILE_WIDTH + ty, Col)是否在 N 的范围内。如果不在,往Nds填 0。 - 存储 P 结果的准入证:在最后写回全局内存时,检查
(Row, Col)是否在 P 的范围内。
4. 为什么要填 0?
这是一个非常巧妙的数学处理。
- 如果在加载瓦片时发现越界,我们不能让线程直接退出(否则
__syncthreads()会死锁),也不能让它乱读。 - 我们让它往共享内存里填一个 0。
- 因为 a × 0 = 0,在后续的累加计算(
Pvalue += Mds... * Nds...)中,这些“虚假”的 0 不会影响最终求和的结果。
总结
简单来说,这段话是告诉你:搬运工和建筑工是两码事。
- 搬运工(Load Data):即使你不住在这一块,你也得帮邻居搬砖。但如果仓库里没砖了(越界),你要搬块空气(填0)回去,不能随便搬别人的。
- 建筑工(Compute P):只有你的地基在规划图内(不越界),你最后才把盖好的房子(Pvalue)交工。
既然谈到了边界处理,你是否想过:在代码中频繁加入
if 判断(Branch)会对 GPU 的 Warp
调度和性能产生什么负面影响吗?
经过边界条件检查,分块矩阵乘法核心距离成为通用矩阵乘法核心仅一步之遥。通常,矩阵乘法定义适用于矩形矩阵:一个 j 乘 k 的 M 矩阵与一个 k 乘 l 的 N 矩阵相乘得到一个 j 乘 l 的 P 矩阵。到目前为止,我们的核心只能处理方阵。
幸运的是,将我们的核心进一步扩展为通用矩阵乘法核心相当容易。我们需要做一些简单的修改。
首先,将 Width 参数替换为三个无符号整数参数:j、k、l。在用于引用 M 的高度或 P 的高度的地方,将 Width 替换为 j。在用于引用 M 的宽度或 N 的高度的地方,将 Width 替换为 k。在用于引用 N 的宽度或 P 的宽度的地方,将 Width 替换为 l。对这些更改后的核心的修改留作练习。
5.6 内存使用对占用率的影响
回顾第四章《计算架构与调度》,我们讨论了最大化 SM 上线程的占用率的重要性,以便能够容忍长延迟操作。核心的内存使用在占用率调优中起着重要作用。虽然 CUDA 寄存器和共享内存可以极大地减少对全局内存的访问次数,但必须小心谨慎地控制这些内存的使用量,以保持在 SM 的容量范围内。每个 CUDA 设备都提供有限的资源,这限制了对于给定应用程序,可以同时驻留在 SM 中的线程数量。一般来说,每个线程需要的资源越多,每个 SM 中可以驻留的线程数量就越少。
我们在第四章《计算架构与调度》中看到,寄存器的使用量可能是占用率的一个限制因素。共享内存的使用量也可能限制可以分配给每个 SM 的线程数量。例如,A100 GPU 的每个 SM 最多可以配置为具有 164 KB 的共享内存,并支持每个 SM 的最大线程数为 2048 个。因此,为了使用所有 2048 个线程槽位,一个线程块不应该使用超过平均值为 (164 KB) / (2048 个线程) = 82 B/线程 的共享内存。在分块矩阵乘法示例中,每个块有 2 × 2 × TILE_WIDTH 个线程,并且为 Mds 使用 TILE_WIDTH × 4B 的共享内存,为 Nds 使用 2 × TILE_WIDTH × 4B 的共享内存。因此,线程块使用的平均共享内存为 (TILE_WIDTH2 × 4B + TILE_WIDTH2 × 4B) / (TILE_WIDTH2 个线程) = 8 B/线程。因此,分块矩阵乘法核心的占用率不受共享内存的限制。
需要注意的是,每个 SM 中共享内存的大小也可能因设备而异。每一代或型号的设备可以具有不同数量的共享内存。通常情况下,希望核心能够根据硬件中可用的共享内存量使用不同的共享内存量。也就是说,我们可能希望主机代码能够动态确定共享内存的大小,并调整核心使用的共享内存量。可以通过调用 cudaGetDeviceProperties 函数来实现这一点。假设变量 &devProp 传递给函数。在这种情况下,字段 devProp.sharedMemPerBlock 给出每个 SM 中可用的共享内存量。程序员然后可以确定每个块应该使用的共享内存量。
不幸的是,图 5.9 和图 5.13 中的核心不支持由主机代码动态调整共享内存使用量。在图 5.9 中使用的声明将其共享内存使用量硬编码为编译时常量:
1 | |
也就是说,无论在编译时将 TILE_WIDTH 设置为何值,Mds 和 Nds 的大小都被设置为 TILE_WIDTH2 个元素。由于代码包含了 Mds 和 Nds,它们都将拥有 256 个元素。如果我们想要改变 Mds 和 Nds 的大小,我们需要改变 TILE_WIDTH 的值并重新编译代码。在不重新编译的情况下,核心不能轻松地在运行时调整其共享内存使用量。
我们可以通过在 CUDA 中使用不同的声明样式来启用这种调整,通过在共享内存声明前添加一个 C extern 关键字并在声明中省略数组的大小。基于这种样式,Mds 和 Nds 的声明需要合并为一个动态分配的数组:
1 | |
由于只有一个合并的数组,我们还需要手动定义数组的 Mds 部分和 Nds 部分的起始位置。请注意,合并的数组是一维的。我们需要使用基于垂直和水平索引的线性化索引来访问它。
在运行时,当我们调用核心时,我们可以根据设备查询结果动态配置每个块使用的共享内存量,并将其作为第三个配置参数提供给核心调用。例如,修订后的核心可以使用以下语句启动:

其中 size_t 是一个内置类型,用于声明变量以保存动态分配的数据结构的大小信息。大小以字节为单位表示。在我们的矩阵乘法示例中,对于一个 16 乘 16 的瓦片,我们有一个大小为 2 乘 16 乘 16 乘 4 = 2048 字节来容纳 Mds 和 Nds。我们省略了在运行时设置 size 值的计算细节,并将其作为读者的练习留下。
在图 5.14 中,我们展示了如何修改图 5.9 和图 5.11 中的核心代码,以使用动态大小的共享内存来存储 Mds 和 Nds 数组。将每个数组部分的大小作为参数传递给核心函数可能也很有用。在这个例子中,我们添加了两个参数:第一个参数是 Mds 部分的大小,第二个参数是 Nds 部分的大小,都以字节为单位。请注意,在上述主机代码中,我们将 size/2 作为这些参数的值,即 1024 字节。通过第 06 和 07 行的赋值,核心代码的其余部分可以使用 Mds 和 Nds 作为数组的基础,并使用线性化索引来访问 Mds 和 Nds 元素。例如,不使用 Mds[ty][tx],而是使用 Mds[ty * TILE_WIDTH+tx]。

总结
这段文字探讨了 CUDA 编程中一个非常实际的工程问题:如何通过管理共享内存(Shared Memory)来优化程序的“占用率(Occupancy)”,并实现代码的灵活性。
以下是核心内容的总结:
1. 占用率的“木桶效应”
程序在 GPU 上的性能往往取决于能同时跑多少个线程(即占用率)。 占用率受限于 SM 的三种资源:寄存器、线程数上限和共享内存。
- 限制逻辑:如果每个线程使用的共享内存太多,SM 剩余的内存就不够分配给更多的线程块,导致线程槽位闲置,占用率下降。
- 示例:在 A100 上,若平均每个线程使用超过 82 字节的共享内存,就无法达到 100% 占用率。 如果每个线程用 132 字节,占用率会降至 62%。
2. 静态分配的局限性
在之前的代码(图 5.9)中,共享内存的大小是用
#define TILE_WIDTH 16 硬编码的。
- 问题:这意味着瓦片大小在编译时就定死了。 如果换了一块显存更小或更大的显卡,你必须修改源码并重新编译才能调整性能,这在实际工程中非常不方便。
3. 动态共享内存(Dynamic Shared Memory)
为了让代码更通用,书中介绍了 extern __shared__
关键字。
- 声明方式:在核函数内部声明一个不带大小的数组:
extern __shared__ float s_array[];。 - 运行时配置:在 CPU 端启动核函数时,通过
<<<grid, block, sharedMemSize>>>的第三个参数动态指定字节数。 - 内部划分:由于动态声明只能有一个数组,如果需要同时存放 Mds 和 Nds,程序员需要手动计算指针偏移量,将这块连续内存拆分成两部分使用。
4. 程序员的优化思路
- 查询设备属性:利用
cudaGetDeviceProperties获取当前显卡每个 SM 实际拥有的共享内存量。 - 自动适配:根据查询结果,动态计算出最合适的
TILE_WIDTH,从而在不同型号的 GPU 上都能自动获得最高的占用率。
总结成一句话: 这章教你不要把资源写死,要学会根据显卡的硬件极限,“量菜吃饭”地动态分配共享内存,从而榨干 GPU 的占用率。
既然你已经了解了动态分配,你想看看图 5.14 中那种“手动划分一维数组”的具体代码逻辑是怎么实现的吗?
5.7 总结
总的来说,现代处理器上程序的执行速度可能会受到内存速度的严重限制。要实现对 CUDA 设备执行吞吐量的良好利用,就需要在内核代码中努力实现高的计算与全局内存访问比率。如果比率较低,那么内核就会受到内存限制,即其执行速度受限于操作数从内存中访问的速率。
CUDA 提供对寄存器、共享内存和常量内存的访问。这些内存比全局内存小得多,但可以以更高的速度访问。要有效地使用这些内存,就需要重新设计算法。我们以矩阵乘法为例,说明了瓦片化是增强数据访问局部性并有效利用共享内存的一种流行策略。在并行编程中,瓦片化使用屏障同步来强制多个线程在执行的每个阶段联合关注输入数据的一个子集,以便将子集数据放入这些特殊的内存类型中,从而实现更高的访问速度。
然而,CUDA 程序员需要注意这些特殊类型内存的有限大小。它们的容量取决于具体的实现。一旦超出了它们的容量,它们就会限制每个 SM 中可以同时执行的线程数量,并可能对 GPU 的计算吞吐量以及其耐受延迟的能力产生负面影响。在开发应用程序时考虑硬件限制的能力是并行编程的一个关键方面。
尽管我们是在 CUDA C 编程的背景下介绍了瓦片化算法,但它是在几乎所有类型的并行计算系统中实现高性能的有效策略。原因在于应用程序必须表现出数据访问的局部性,以便在这些系统中有效利用高速内存。例如,在多核 CPU 系统中,数据局部性可以使应用程序有效地使用芯片内数据缓存,从而降低内存访问延迟并实现高性能。这些芯片内数据缓存也具有有限的大小,并且需要计算表现出局部性。因此,当开发其他类型的并行计算系统的并行应用程序时,读者也会发现瓦片化算法很有用,使用其他编程模型。
本章的目标是介绍局部性、瓦片化以及不同的 CUDA 内存类型的概念(通过优化分块矩阵乘法 -> GEMM)。我们介绍了使用共享内存的瓦片矩阵乘法核心。我们进一步研究了需要边界测试条件来允许在应用瓦片化技术时处理任意数据维度的需求。我们还简要讨论了动态大小的共享内存分配的使用,以便内核可以根据硬件能力调整每个块使用的共享内存大小。我们没有讨论在瓦片化中使用寄存器(Thread tiling)。在本书第二部分讨论并行算法模式时,我们将解释在瓦片化算法中使用寄存器的情况。
我现在对tile大概有理解了但还有疑惑,比如说分块矩阵索引的计算用的是blockIdx * tile-width而不是block-size,是因为在最开始设置核函数入口的块个数时候用的大小就是tile-width,这样是不是相当于tile替换了block的作用,相当于是个重命名?还有就是Tiling的核心是分块还是使用shared memory协作?因为block本来就有分块的作用,但是如果核心是后者那为什么不叫“使用共享内存”的方法而是”tile“这个名字?
提出的这两个问题其实涉及了 硬件抽象 与 算法设计 之间的本质区别。
我们直接切入核心:
1. TILE_WIDTH
是 Block Size 的“重命名”吗?
在图 5.9 的基础代码中,它们的数值确实是相等的,但这不仅仅是重命名,而是语义上的对齐。
blockDim(硬件维度):它描述的是 “执行任务的工人有多少”。这是 CUDA 硬件层面的固有属性。TILE_WIDTH(算法维度):它描述的是 “我们要搬的数据块有多大”。这是算法逻辑层面的属性。
为什么代码里写 bx * TILE_WIDTH 而不是 bx * blockDim.x?
因为在 CPU 端配置网格(Grid)时,我们是按照数据的瓦片大小来划分块数的。比如:
dim3 grid(Width / TILE_WIDTH, Height / TILE_WIDTH);
这时候,blockIdx 的每一个增量,代表的是在矩阵上跳过了一个 TILE_WIDTH 长度的数据块。
关键区别: 如果以后你进行更高级的优化(比如 Thread Tiling),让一个线程块负责处理两个并排的瓦片,那么:
你的
blockDim.x可能还是 16。但你的 TILE_WIDTH 可能是 32。
此时,bx * 16 就会让你跳错位置,只有 bx * 32 才是正确的。所以,使用 TILE_WIDTH 是为了让索引计算与数据划分的逻辑挂钩,而不是死死绑定在硬件线程数上。
2. Tiling 的核心:是“分块”还是“协作”?
你的直觉很准。如果只说“分块”,CUDA 的 Thread Block
已经做到了;如果只说“协作”,任何共享内存的使用都是协作。
Tiling 的核心定义是:通过“分块”来实现“数据的局部重用(Data Reuse)”。
我们可以从以下两个维度来理解为什么它叫这个名字:
A. 为什么不叫“共享内存法”?
“共享内存”只是一个存储介质(就像冰箱)。你可以往冰箱里放任何东西,比如一个查找表(Lookup Table),那不叫 Tiling。
Tiling 描述的是一种特定的动作:像贴瓷砖一样,把巨大的数据(全局内存)拆成一小块一小块,轮流搬进冰箱里处理。
- 如果你只是用共享内存存个临时变量,那不是 Tiling。
- 只有当你为了减少全局内存流量,把原本要多次从大仓库读的数据,一次性“分块”搬进小仓库并反复使用时,才叫 Tiling。
B. 协作是手段,重用是目的
“协作”是 Tiling 能够成功的物理手段。
在矩阵乘法中,Tiling 强迫一个块里的所有线程“步调一致”地工作(通过 ph 循环和屏障同步)。这种强迫带来的好处是:原本每个线程都要去全局内存读一次的数据,现在大家合伙读一次就够了。
- 分块(Partitioning):解决了共享内存装不下的问题。
- 协作(Collaboration):解决了如何最高效率把这块数据搬进来的问题。
- 重用(Reuse):才是 Tiling 最终在 Roofline 模型上帮你把点向右推、提高性能的根本原因。
3. 深度总结:Block vs. Tile
| 概念 | 归属层级 | 描述对象 | 作用 |
|---|---|---|---|
| Block | 硬件/驱动层 | 线程的组织单位 | 决定了资源(寄存器、SM)的分配 |
| Tile | 算法/逻辑层 | 数据的划分单位 | 决定了内存访问的局部性和重用率 |
所以,为什么叫 Tiling 而不是别的?
因为它强调的是数据管理策略。就像铺地板,地板很大(Global Memory),你手里只有一块瓷砖(Shared Memory)。你必须一小块一小块地铺,每一块铺好了再挪到下一处。
“Tile 不单指“对数据分块”,还在描述将大的全局内存分成小的“瓦片,瓷砖”贴到小的共享内存中的Tiling的协作过程的结果!”